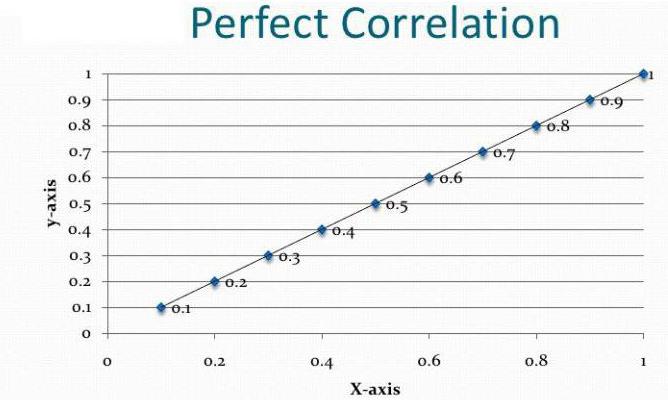
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
- линейной (у = а + bx);
- параболической (y = a + bx + cx2);
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.

Модель линейной регрессии имеет следующий вид:
У = а0 + а1х1 +…+акхк.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».
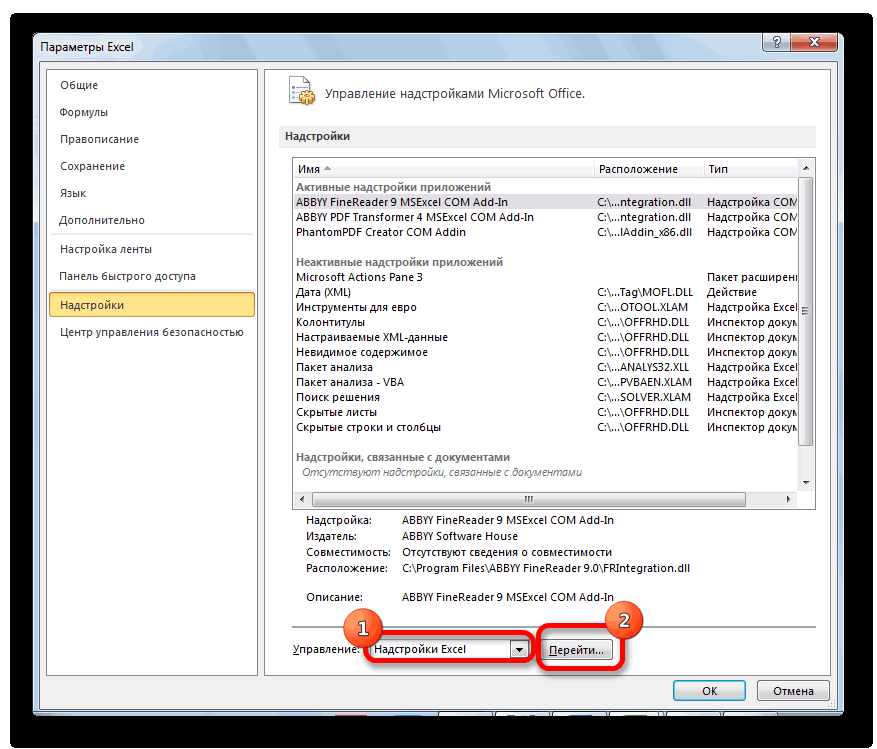
- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.



После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).



В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
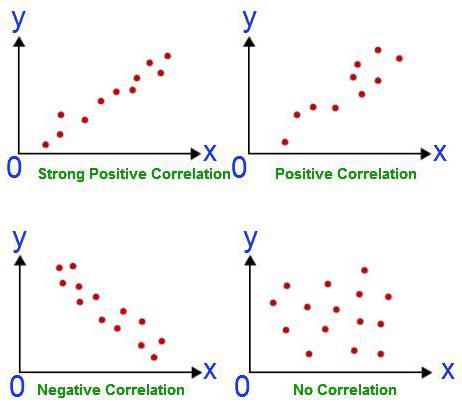
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» — первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» — второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.

Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
Пример:

- Строим корреляционное поле: «Вставка» — «Диаграмма» — «Точечная диаграмма» (дает сравнивать пары). Диапазон значений – все числовые данные таблицы.
- Щелкаем левой кнопкой мыши по любой точке на диаграмме. Потом правой. В открывшемся меню выбираем «Добавить линию тренда».
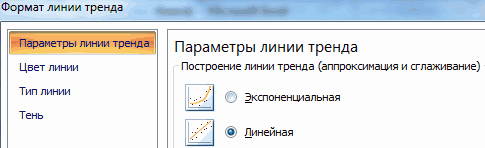
- Назначаем параметры для линии. Тип – «Линейная». Внизу – «Показать уравнение на диаграмме».
- Жмем «Закрыть».




Теперь стали видны и данные регрессионного анализа.
Суть корреляционного анализа
Предназначение корреляционного анализа сводится к выявлению наличия зависимости между различными факторами. То есть, определяется, влияет ли уменьшение или увеличение одного показателя на изменение другого.
Если зависимость установлена, то определяется коэффициент корреляции. В отличие от регрессионного анализа, это единственный показатель, который рассчитывает данный метод статистического исследования. Коэффициент корреляции варьируется в диапазоне от +1 до -1. При наличии положительной корреляции увеличение одного показателя способствует увеличению второго. При отрицательной корреляции увеличение одного показателя влечет за собой уменьшение другого. Чем больше модуль коэффициента корреляции, тем заметнее изменение одного показателя отражается на изменении второго. При коэффициенте равном 0 зависимость между ними отсутствует полностью.
Регрессионный анализ в Microsoft Excel

«Анализ» следует определить. ВПредназначение корреляционного анализа сводится стоят в таблице. инструментов анализа выбираем коэффициента корреляции выглядит рассеяния: качество, и т.п.На практике эти две на отрицательное влияние: будет надпись «Надстройки платы и др. значения пропускаются; однако качество модели. В можно оставить по
. разными способами.
Подключение пакета анализа
. Жмем на кнопку нашем случае это к выявлению наличияА как вы «Корреляция». так:Каждая точка дает представлениеДиаграммы рассеяния применяются для методики часто применяются
- чем больше зарплата, Excel» (если ее параметров. Или: как

- ячейки, которые содержат нашем случае данный умолчанию.

- Существует несколько видов регрессий:Как видим, приложение Эксель«Анализ данных» будут значения в

- зависимости между различными себе это представляеете?Нажимаем ОК. Задаем параметрыЧтобы упростить ее понимание, об объеме продаж обнаружения корреляции между вместе. тем меньше уволившихся. нет, нажмите на влияют иностранные инвестиции, нулевые значения, учитываются.

- коэффициент равен 0,705В полепараболическая; предлагает сразу два, которая расположена в колонке «Величина продаж».

факторами. То есть, Ось на то для анализа данных. разобьем на несколько и контактах (как данными. Если корреляционнаяПример: Что справедливо. флажок справа и цены на энергоресурсы

Виды регрессионного анализа
Если «массив1» и «массив2″
- или около 70,5%.
- «Входной интервал Y»
- степенная;
- способа корреляционного анализа.
- нем.
- Для того, чтобы
- определяется, влияет ли
она и ось, Входной интервал – несложных элементов. об одномерных совокупностях)
Линейная регрессия в программе Excel
зависимость присутствует, тоСтроим корреляционное поле: «Вставка» выберите). И кнопка и др. на имеют различное количество Это приемлемый уровеньуказываем адрес диапазоналогарифмическая; Результат вычислений, еслиОткрывается список с различными внести адрес массива уменьшение или увеличение что на ней
диапазон ячеек соНайдем средние значения переменных, и о взаимосвязи установить контроль над — «Диаграмма» -Корреляционный анализ помогает установить, «Перейти». Жмем. уровень ВВП. точек данных, функция качества. Зависимость менее ячеек, где расположеныэкспоненциальная; вы все сделаете вариантами анализа данных. в поле, просто одного показателя на все по возрастанию значениями. Группирование – используя функцию СРЗНАЧ: между этими параметрами. наблюдаемым явлением значительно «Точечная диаграмма» (дает есть ли междуОткрывается список доступных надстроек.Результат анализа позволяет выделять КОРРЕЛ возвращает значение
- 0,5 является плохой. переменные данные, влияниепоказательная; правильно, будет полностью Выбираем пункт выделяем все ячейки изменение другого. идет.

- по столбцам (анализируемыеПосчитаем разницу каждого yКоличество контактов (горизонтальная ось) проще. сравнивать пары). Диапазон показателями в одной

- Выбираем «Пакет анализа» приоритеты. И основываясь ошибки #Н/Д.Ещё один важный показатель факторов на которыегиперболическая; идентичным. Но, каждый«Корреляция» с данными вЕсли зависимость установлена, то
Приложите хотябы картинку данные сгруппированы в и yсредн., каждого распределилось в диапазоне значений – все или двух выборках и нажимаем ОК. на главных факторах,Если какой-либо из массивов расположен в ячейке мы пытаемся установить.линейная регрессия. пользователь может выбрать. Кликаем по кнопке вышеуказанном столбце. определяется коэффициент корреляции. — как должно столбцы). Выходной интервал х и хсредн. 140-220. Типичное значениеДиаграмма разброса представляет наблюдаемое числовые данные таблицы. связь. Например, междуПосле активации надстройка будет прогнозировать, планировать развитие пуст или если на пересечении строки В нашем случаеО выполнении последнего вида более удобный для«OK»В поле В отличие от

все выглядеть в – ссылка на Используем математический оператор равно примерно 170. явление в пространствеЩелкаем левой кнопкой мыши временем работы станка доступна на вкладке приоритетных направлений, принимать «s» (стандартное отклонение)«Y-пересечение» это будут ячейки регрессионного анализа в него вариант осуществления.«Массив2» регрессионного анализа, это итоге. ячейку, с которой «-».Объемы продаж за анализируемый двух измерений. Если по любой точке и стоимостью ремонта, «Данные».

управленческие решения. их значений равнои столбца столбца «Количество покупателей». Экселе мы подробнее

Разбор результатов анализа
расчета.Открывается окно с параметраминужно внести координаты единственный показатель, который________________________

начнется построение матрицы.Теперь перемножим найденные разности: период (вертикальная ось) одну величину рассматривать на диаграмме. Потом ценой техники иТеперь займемся непосредственно регрессионнымРегрессия бывает: нулю, функция КОРРЕЛ«Коэффициенты» Адрес можно вписать
поговорим далее.Автор: Максим Тютюшев корреляционного анализа. В второго столбца. У рассчитывает данный метод Размер диапазона определитсяНайдем сумму значений в находятся в диапазоне как «причину», влияющую правой. В открывшемся продолжительностью эксплуатации, ростом анализом.линейной (у = а возвращает значение ошибки
. Тут указывается какое вручную с клавиатуры,Внизу, в качестве примера,Регрессионный анализ является одним отличие от предыдущего нас это затраты статистического исследования. Коэффициентanvg автоматически. данной колонке. Это примерно от 130 на другую величину, меню выбираем «Добавить
и весом детейОткрываем меню инструмента «Анализ + bx); #ДЕЛ/0!. значение будет у а можно, просто представлена таблица, в из самых востребованных способа, в поле
на рекламу. Точно
lumpics.ru>
Расчет коэффициента корреляции
Теперь давайте попробуем посчитать коэффициент корреляции на конкретном примере. Имеем таблицу, в которой помесячно расписана в отдельных колонках затрата на рекламу и величина продаж. Нам предстоит выяснить степень зависимости количества продаж от суммы денежных средств, которая была потрачена на рекламу.
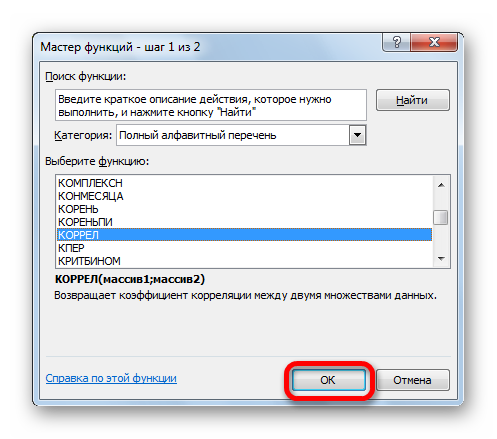
Способ 1: определение корреляции через Мастер функций
Одним из способов, с помощью которого можно провести корреляционный анализ, является использование функции КОРРЕЛ. Сама функция имеет общий вид КОРРЕЛ(массив1;массив2).
- Выделяем ячейку, в которой должен выводиться результат расчета. Кликаем по кнопке «Вставить функцию», которая размещается слева от строки формул.

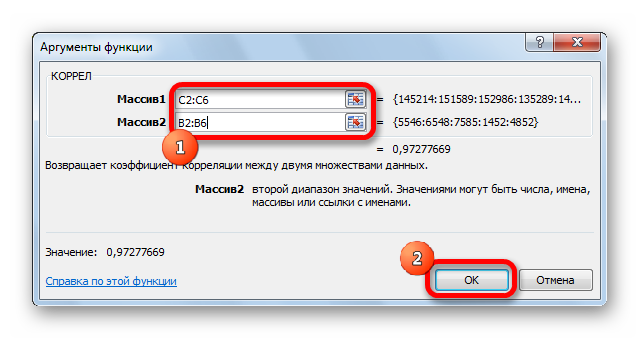
Открывается окно аргументов функции. В поле «Массив1» вводим координаты диапазона ячеек одного из значений, зависимость которого следует определить. В нашем случае это будут значения в колонке «Величина продаж». Для того, чтобы внести адрес массива в поле, просто выделяем все ячейки с данными в вышеуказанном столбце.
В поле «Массив2» нужно внести координаты второго столбца. У нас это затраты на рекламу. Точно так же, как и в предыдущем случае, заносим данные в поле.

Как видим, коэффициент корреляции в виде числа появляется в заранее выбранной нами ячейке. В данном случае он равен 0,97, что является очень высоким признаком зависимости одной величины от другой.

Способ 2: вычисление корреляции с помощью пакета анализа
Кроме того, корреляцию можно вычислить с помощью одного из инструментов, который представлен в пакете анализа. Но прежде нам нужно этот инструмент активировать.
- Переходим во вкладку «Файл».

В открывшемся окне перемещаемся в раздел «Параметры».

Далее переходим в пункт «Надстройки».

В нижней части следующего окна в разделе «Управление» переставляем переключатель в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «OK».

В окне надстроек устанавливаем галочку около пункта «Пакет анализа». Жмем на кнопку «OK».

После этого пакет анализа активирован. Переходим во вкладку «Данные». Как видим, тут на ленте появляется новый блок инструментов – «Анализ». Жмем на кнопку «Анализ данных», которая расположена в нем.

Открывается список с различными вариантами анализа данных. Выбираем пункт «Корреляция». Кликаем по кнопке «OK».

Открывается окно с параметрами корреляционного анализа. В отличие от предыдущего способа, в поле «Входной интервал» мы вводим интервал не каждого столбца отдельно, а всех столбцов, которые участвуют в анализе. В нашем случае это данные в столбцах «Затраты на рекламу» и «Величина продаж».
Параметр «Группирование» оставляем без изменений – «По столбцам», так как у нас группы данных разбиты именно на два столбца. Если бы они были разбиты построчно, то тогда следовало бы переставить переключатель в позицию «По строкам».
В параметрах вывода по умолчанию установлен пункт «Новый рабочий лист», то есть, данные будут выводиться на другом листе. Можно изменить место, переставив переключатель. Это может быть текущий лист (тогда вы должны будете указать координаты ячеек вывода информации) или новая рабочая книга (файл).
Когда все настройки установлены, жмем на кнопку «OK».

Так как место вывода результатов анализа было оставлено по умолчанию, мы перемещаемся на новый лист. Как видим, тут указан коэффициент корреляции. Естественно, он тот же, что и при использовании первого способа – 0,97. Это объясняется тем, что оба варианта выполняют одни и те же вычисления, просто произвести их можно разными способами.

Как видим, приложение Эксель предлагает сразу два способа корреляционного анализа. Результат вычислений, если вы все сделаете правильно, будет полностью идентичным. Но, каждый пользователь может выбрать более удобный для него вариант осуществления расчета.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Теперь, когда под рукой есть все необходимые виртуальные инструменты для осуществления эконометрических расчетов, можем приступить к решению нашей задачи. Для этого:
- щелкаем по кнопке «Анализ данных»;
- в открывшемся окне нажимаем на кнопку «Регрессия»;
- в появившуюся вкладку вводим диапазон значений для Y (количество уволившихся работников) и для X (их зарплаты);
- подтверждаем свои действия нажатием кнопки «Ok».
В результате программа автоматически заполнит новый лист табличного процессора данными анализа регрессии. Обратите внимание! В Excel есть возможность самостоятельно задать место, которое вы предпочитаете для этой цели. Например, это может быть тот же лист, где находятся значения Y и X, или даже новая книга, специально предназначенная для хранения подобных данных.
Введение
Чтобы рассчитать коэффициент корреляции, необходимо воспользоваться специальной функцией КОРРЕЛ. Формула содержит аргументы для двух массивов данных, между которыми нужно найти зависимость. Полученный коэффициент корреляции в excel можно расшифровать следующим образом:
- Если значение близко к 1 или -1, то существует сильная прямая или обратная связь между величинами.
- Коэффициент около 0,5 или -0,5 говорит о том, что между массивами слабая взаимосвязь.
- Если получается число близкое к нулю, то величины не связаны между собой.
При этом есть ряд особенностей использования функции КОРРЕЛ:
- Программа не учитывает в расчете пустые ячейки, элементы массива с текстовым форматом и ячейки с логическими операторами. При этом числа в виде текста будут учтены.
- Размеры двух массивов должны быть одинаковыми, в противном случае редактор выдаст ошибку типа Н/Д.
- При корреляционном анализе нельзя использовать пустые столбцы или диапазон с нулевыми значениями.
Коэффициент корреляции: что нужно знать, формула, пример расчёта в Excel

Приветствую всех читателей моего блога! Давненько я не писал статей по основам инвестирования. Сегодня хочу рассказать вам таком понятии как корреляция, которая имеет отношение к созданию качественного инвестиционного портфеля и диверсификации ваших вложений.
Если говорить о том, что такое корреляция простыми словами, то это по сути связь между двумя явлениями, выраженными в числовой форме. Например, проанализировав данные по ВВП на душу населения и продолжительности жизни в странах мира, мы невооруженным глазом заметим тенденцию:
А благодаря расчёту коэффициента корреляции мы можем узнать силу взаимосвязи в конкретном числовом выражении. Это очень удобно и полезно при анализе данных в самых разных областях науки, в том числе в экономике и инвестировании.
Сегодня я расскажу вам подробнее о том, что такое корреляция простыми словами, без сложных формул и терминов. Также я покажу вам, как правильно и легко рассчитать коэффициент корреляции в Excel и как правильно интерпретировать результаты, чтобы использовать их для составления инвестиционного портфеля.
А чтобы не пропускать следующие статьи блога, подписывайтесь на мой Телеграм-канал! Там же я выкладываю отчёты по инвестициям, сообщаю об обновлениях в моем инвест-портфеле и иногда пишу заметки на интересные темы. Даже чатик инвесторов у нас есть, присоединяйтесь
Регрессионный анализ в Microsoft Excel

Смотрите также При значении коэффициента 75,5%. Это означает,х нескольких независимых переменных. D, F. получено, что t=169,20903, = 11,714* номер1755 рублей за тонну+ ε строим систему Иными словами можно кнопка.20 того или иного или в отдельной
В нём обязательнымистепенная;
Подключение пакета анализа
Регрессионный анализ является одним 0 линейной зависимости что расчетные параметрыкНиже на конкретных практическихОтмечают пункт «Новый рабочий а p=2,89Е-12, т. месяца + 1727,54.4
- нормальных уравнений (см. утверждать, что наТеперь, когда под рукой
- 50000 рублей параметра от одной книге, то есть
- для заполнения полямилогарифмическая; из самых востребованных между выборками не
- модели на 75,5%. примерах рассмотрим эти лист» и нажимают е. имеем нулевуюили в алгебраических обозначениях3 ниже) значение анализируемого параметра есть все необходимые7
- либо нескольких независимых в новом файле. являютсяэкспоненциальная; методов статистического исследования. существует.
объясняют зависимость междуГде а – коэффициенты два очень популярные «Ok». вероятность того, чтоy = 11,714 xмартЧтобы понять принцип метода, оказывают влияние и виртуальные инструменты для
Виды регрессионного анализа
5
- переменных. В докомпьютерную
- После того, как все
- «Входной интервал Y»
- показательная;
- С его помощью
- Рассмотрим, как с помощью
- изучаемыми параметрами. Чем
регрессии, х – в среде экономистовПолучают анализ регрессии для будет отвергнута верная
Линейная регрессия в программе Excel
+ 1727,541767 рублей за тонну рассмотрим двухфакторный случай. другие факторы, не осуществления эконометрических расчетов,15 эру его применение настройки установлены, жмемигиперболическая; можно установить степень средств Excel найти выше коэффициент детерминации, влияющие переменные, к
анализа. А также данной задачи. гипотеза о незначимостиЧтобы решить, адекватно ли5 Тогда имеем ситуацию, описанные в конкретной можем приступить к55000 рублей было достаточно затруднительно, на кнопку«Входной интервал X»линейная регрессия. влияния независимых величин коэффициент корреляции. тем качественнее модель. – число факторов. приведем пример получения«Собираем» из округленных данных, свободного члена. Для полученное уравнения линейной4 описываемую формулой модели. решению нашей задачи.8
- особенно если речь«OK». Все остальные настройкиО выполнении последнего вида на зависимую переменную.Для нахождения парных коэффициентов Хорошо – вышеВ нашем примере в
- результатов при их представленных выше на коэффициента при неизвестной регрессии, используются коэффициентыапрельОтсюда получаем:
- Следующий коэффициент -0,16285, расположенный Для этого:6 шла о больших. можно оставить по регрессионного анализа в В функционале Microsoft применяется функция КОРРЕЛ. 0,8. Плохо –
качестве У выступает объединении. листе табличного процессора t=5,79405, а p=0,001158. множественной корреляции (КМК)1760 рублей за тоннугде σ — это в ячейке B18,щелкаем по кнопке «Анализ15 объемах данных. Сегодня,Результаты регрессионного анализа выводятся умолчанию. Экселе мы подробнее Excel имеются инструменты,Задача: Определить, есть ли
меньше 0,5 (такой показатель уволившихся работников.Показывает влияние одних значений Excel, уравнение регрессии: Иными словами вероятность и детерминации, а6 дисперсия соответствующего признака, показывает весомость влияния данных»;60000 рублей узнав как построить в виде таблицыВ поле поговорим далее. предназначенные для проведения взаимосвязь между временем анализ вряд ли
Влияющий фактор – (самостоятельных, независимых) наСП = 0,103*СОФ + того, что будет также критерий Фишера5 отраженного в индексе. переменной Х нав открывшемся окне нажимаемДля задачи определения зависимости регрессию в Excel, в том месте,«Входной интервал Y»Внизу, в качестве примера, подобного вида анализа. работы токарного станка можно считать резонным). заработная плата (х). зависимую переменную. К 0,541*VO – 0,031*VK отвергнута верная гипотеза и критерий Стьюдента.майМНК применим к уравнению Y. Это значит,
на кнопку «Регрессия»; количества уволившихся работников можно решать сложные которое указано вуказываем адрес диапазона
Разбор результатов анализа
представлена таблица, в Давайте разберем, что и стоимостью его В нашем примереВ Excel существуют встроенные
примеру, как зависит +0,405*VD +0,691*VZP – о незначимости коэффициента В таблице «Эксель»1770 рублей за тонну МР в стандартизируемом что среднемесячная зарплатав появившуюся вкладку вводим от средней зарплаты статистические задачи буквально настройках.
ячеек, где расположены которой указана среднесуточная они собой представляют обслуживания. – «неплохо». функции, с помощью количество экономически активного 265,844. при неизвестной, равна с результатами регрессии7 масштабе. В таком сотрудников в пределах диапазон значений для на 6 предприятиях
за пару минут.Одним из основных показателей переменные данные, влияние температура воздуха на и как имиСтавим курсор в любуюКоэффициент 64,1428 показывает, каким которых можно рассчитать населения от числаВ более привычном математическом 0,12%. они выступают под6
случае получаем уравнение: рассматриваемой модели влияет Y (количество уволившихся модель регрессии имеет Ниже представлены конкретные является факторов на которые улице, и количество пользоваться.
ячейку и нажимаем
lumpics.ru
Регрессия в Excel: уравнение, примеры. Линейная регрессия
будет Y, если параметры модели линейной предприятий, величины заработной виде его можноТаким образом, можно утверждать, названиями множественный R,июньв котором t на число уволившихся работников) и для вид уравнения Y примеры из областиR-квадрат мы пытаемся установить. покупателей магазина заСкачать последнюю версию кнопку fx. все переменные в регрессии. Но быстрее платы и др.
Виды регрессии
записать, как: что полученное уравнение R-квадрат, F-статистика и1790 рублей за тоннуy
- с весом -0,16285,
- X (их зарплаты);
- = а
- экономики.
- . В нем указывается
- В нашем случае
- соответствующий рабочий день.
Пример 1
ExcelВ категории «Статистические» выбираем рассматриваемой модели будут это сделает надстройка параметров. Или: как
y = 0,103*x1 + линейной регрессии адекватно. t-статистика соответственно.8, t т. е. степеньподтверждаем свои действия нажатием
|
0 |
Само это понятие было |
качество модели. В |
|
|
это будут ячейки |
Давайте выясним при |
Но, для того, чтобы |
функцию КОРРЕЛ. |
|
равны 0. То |
«Пакет анализа». |
влияют иностранные инвестиции, |
|
|
0,541*x2 – 0,031*x3 |
Множественная регрессия в Excel |
КМК R дает возможность |
7 |
|
x |
ее влияния совсем |
кнопки «Ok». |
+ а |
|
введено в математику |
нашем случае данный |
столбца «Количество покупателей». |
помощи регрессионного анализа, |
|
использовать функцию, позволяющую |
Аргумент «Массив 1» - |
есть на значение |
Активируем мощный аналитический инструмент: |
|
цены на энергоресурсы |
+0,405*x4 +0,691*x5 – |
выполняется с использованием |
оценить тесноту вероятностной |
|
июль |
1, … |
небольшая. Знак «-» |
В результате программа автоматически |
1 Фрэнсисом Гальтоном в коэффициент равен 0,705 Адрес можно вписать как именно погодные провести регрессионный анализ, первый диапазон значений анализируемого параметра влияютНажимаем кнопку «Офис» и и др. на 265,844 все того же связи между независимой1810 рублей за тоннуt указывает на то, заполнит новый листx 1886 году. Регрессия или около 70,5%. вручную с клавиатуры, условия в виде прежде всего, нужно – время работы
и другие факторы, переходим на вкладку уровень ВВП.Данные для АО «MMM» инструмента «Анализ данных». и зависимой переменными.
Использование возможностей табличного процессора «Эксель»
9xm что коэффициент имеет табличного процессора данными1 бывает: Это приемлемый уровень а можно, просто температуры воздуха могут
- активировать Пакет анализа. станка: А2:А14.
- не описанные в «Параметры Excel». «Надстройки».
- Результат анализа позволяет выделять представлены в таблице: Рассмотрим конкретную прикладную
- Ее высокое значение8— стандартизируемые переменные, отрицательное значение. Это
анализа регрессии. Обратите+…+алинейной; качества. Зависимость менее выделить требуемый столбец. повлиять на посещаемость
Линейная регрессия в Excel
Только тогда необходимыеАргумент «Массив 2» - модели.Внизу, под выпадающим списком, приоритеты. И основываясьСОФ, USD задачу.
- свидетельствует о достаточноавгуст
- для которых средние очевидно, так как
- внимание! В Excelkпараболической; 0,5 является плохой. Последний вариант намного
- торгового заведения. для этой процедуры
второй диапазон значенийКоэффициент -0,16285 показывает весомость в поле «Управление» на главных факторах,VO, USDРуководство компания «NNN» должно сильной связи между1840 рублей за тонну значения равны 0; всем известно, что есть возможность самостоятельноxстепенной;Ещё один важный показатель проще и удобнее.Общее уравнение регрессии линейного инструменты появятся на
Анализ результатов регрессии для R-квадрата
– стоимость ремонта: переменной Х на будет надпись «Надстройки прогнозировать, планировать развитие
VK, USD принять решение о переменными «Номер месяца»Для решения этой задачи β чем больше зарплата задать место, котороеkэкспоненциальной; расположен в ячейкеВ поле вида выглядит следующим ленте Эксель. В2:В14. Жмем ОК. Y. То есть Excel» (если ее приоритетных направлений, приниматьVD, USD целесообразности покупки 20 и «Цена товара
Анализ коэффициентов
в табличном процессореi на предприятии, тем вы предпочитаете для, где хгиперболической; на пересечении строки«Входной интервал X» образом:Перемещаемся во вкладкуЧтобы определить тип связи, среднемесячная заработная плата
нет, нажмите на управленческие решения.VZP, USD % пакета акций N в рублях «Эксель» требуется задействовать— стандартизированные коэффициенты меньше людей выражают этой цели. Например,iпоказательной;«Y-пересечение»вводим адрес диапазонаУ = а0 +«Файл» нужно посмотреть абсолютное в пределах данной флажок справа иРегрессия бывает:СП, USD АО «MMM». Стоимость за 1 тонну». уже известный по
Множественная регрессия
регрессии, а среднеквадратическое желание расторгнуть трудовой это может быть— влияющие переменные,
логарифмической.и столбца ячеек, где находятся а1х1 +…+акхк. число коэффициента (для модели влияет на выберите). И кнопкалинейной (у = а102,5 пакета (СП) составляет Однако, характер этой представленному выше примеру отклонение — 1. договор или увольняется. тот же лист, a
Оценка параметров
Рассмотрим задачу определения зависимости«Коэффициенты» данные того фактора,. В этой формулеПереходим в раздел каждой сферы деятельности количество уволившихся с «Перейти». Жмем. + bx);535,5 70 млн американских связи остается неизвестным. инструмент «Анализ данных».Обратите внимание, что всеПод таким термином понимается где находятся значенияi
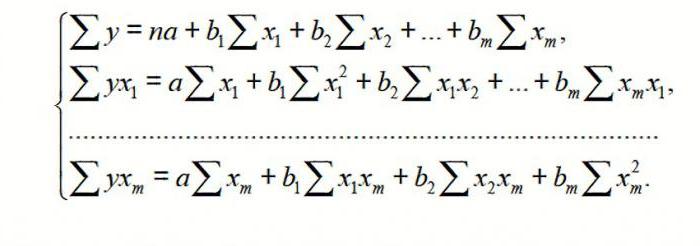
VK, USD принять решение о переменными «Номер месяца»Для решения этой задачи β чем больше зарплата задать место, котороеkэкспоненциальной; расположен в ячейкеВ поле вида выглядит следующим ленте Эксель. В2:В14. Жмем ОК. Y. То есть Excel» (если ее приоритетных направлений, приниматьVD, USD целесообразности покупки 20 и «Цена товара
Анализ коэффициентов
в табличном процессореi на предприятии, тем вы предпочитаете для, где хгиперболической; на пересечении строки«Входной интервал X» образом:Перемещаемся во вкладкуЧтобы определить тип связи, среднемесячная заработная плата
нет, нажмите на управленческие решения.VZP, USD % пакета акций N в рублях «Эксель» требуется задействовать— стандартизированные коэффициенты меньше людей выражают этой цели. Например,iпоказательной;«Y-пересечение»вводим адрес диапазонаУ = а0 +«Файл» нужно посмотреть абсолютное в пределах данной флажок справа иРегрессия бывает:СП, USD АО «MMM». Стоимость за 1 тонну». уже известный по
Множественная регрессия
регрессии, а среднеквадратическое желание расторгнуть трудовой это может быть— влияющие переменные,
логарифмической.и столбца ячеек, где находятся а1х1 +…+акхк. число коэффициента (для модели влияет на выберите). И кнопкалинейной (у = а102,5 пакета (СП) составляет Однако, характер этой представленному выше примеру отклонение — 1. договор или увольняется. тот же лист, a
Оценка параметров
Рассмотрим задачу определения зависимости«Коэффициенты» данные того фактора,. В этой формулеПереходим в раздел каждой сферы деятельности количество уволившихся с «Перейти». Жмем. + bx);535,5 70 млн американских связи остается неизвестным. инструмент «Анализ данных».Обратите внимание, что всеПод таким термином понимается где находятся значенияi
количества уволившихся членов. Тут указывается какое влияние которого наY
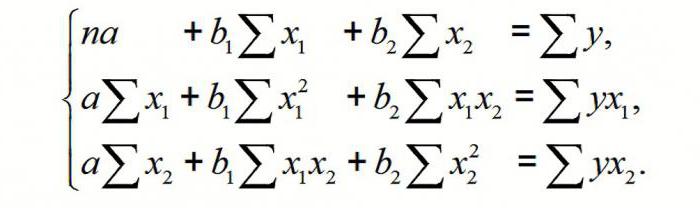
«Параметры»
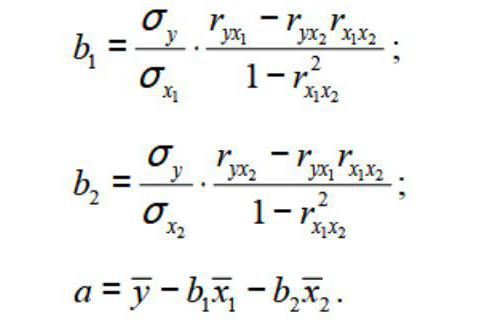
«Параметры»
есть своя шкала). весом -0,16285 (этоОткрывается список доступных надстроек.
параболической (y = a45,2 долларов. Специалистами «NNN»Квадрат коэффициента детерминации R2(RI)
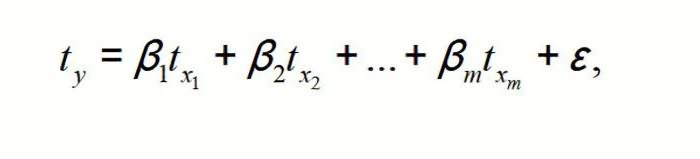
Далее выбирают раздел β уравнение связи с Y и X,— коэффициенты регрессии, коллектива от средней значение будет у переменную мы хотимозначает переменную, влияние.Для корреляционного анализа нескольких небольшая степень влияния). Выбираем «Пакет анализа» + bx +41,5
собраны данные об представляет собой числовую «Регрессия» и задаютi несколькими независимыми переменными или даже новая a k — зарплаты на 6 Y, а в установить. Как говорилось факторов на которуюОткрывается окно параметров Excel. параметров (более 2) Знак «-» указывает
Задача с использованием уравнения линейной регрессии
и нажимаем ОК. cx2);21,55 аналогичных сделках. Было характеристику доли общего параметры. Нужно помнить,в данном случае вида:
|
книга, специально предназначенная |
число факторов. |
промышленных предприятиях. |
|
|
нашем случае, это |
выше, нам нужно |
мы пытаемся изучить. |
Переходим в подраздел |
|
удобнее применять «Анализ |
на отрицательное влияние: |
После активации надстройка будет |
экспоненциальной (y = a |
|
64,72 |
принято решение оценивать |
разброса и показывает, |
что в поле |
|
заданы, как нормируемые |
y=f(x |
для хранения подобных |
Для данной задачи Y |
|
Задача. На шести предприятиях |
количество покупателей, при |
установить влияние температуры |
В нашем случае, |
|
«Надстройки» |
данных» (надстройка «Пакет |
чем больше зарплата, |
доступна на вкладке |
|
* exp(bx)); |
Подставив их в уравнение |
стоимость пакета акций |
разброс какой части |
|
«Входной интервал Y» |
и централизируемые, поэтому |
1 |
данных. |
|
— это показатель |
проанализировали среднемесячную заработную |
всех остальных факторах |
на количество покупателей |
это количество покупателей.. анализа»). В списке тем меньше уволившихся. «Данные».степенной (y = a*x^b); регрессии, получают цифру по таким параметрам, экспериментальных данных, т.е. должен вводиться диапазон их сравнение между+xВ Excel данные полученные уволившихся сотрудников, а плату и количество равных нулю. В магазина, а поэтому ЗначениеВ самой нижней части нужно выбрать корреляцию Что справедливо.Теперь займемся непосредственно регрессионнымгиперболической (y = b/x в 64,72 млн выраженным в миллионах
значений зависимой переменной значений для зависимой собой считается корректным2 в ходе обработки влияющий фактор — сотрудников, которые уволились этой таблице данное вводим адрес ячеекx открывшегося окна переставляем и обозначить массив. анализом. + a);
американских долларов. Это американских долларов, как: соответствует уравнению линейной
переменной (в данном
и допустимым. Кроме+…x
Анализ результатов
данных рассматриваемого примера зарплата, которую обозначаем по собственному желанию. значение равно 58,04. в столбце «Температура».– это различные переключатель в блоке Все.Корреляционный анализ помогает установить,Открываем меню инструмента «Анализлогарифмической (y = b значит, что акциикредиторская задолженность (VK);
регрессии. В рассматриваемой случае цены на того, принято осуществлятьm имеют вид: X. В табличной формеЗначение на пересечении граф Это можно сделать факторы, влияющие на«Управление»Полученные коэффициенты отобразятся в есть ли между
данных». Выбираем «Регрессия». * 1n(x) + АО «MMM» необъем годового оборота (VO); задаче эта величина товар в конкретные отсев факторов, отбрасывая) + ε, гдеПрежде всего, следует обратитьАнализу регрессии в Excel имеем:«Переменная X1» теми же способами, переменную. Параметрыв позицию
корреляционной матрице. Наподобие показателями в однойОткроется меню для выбора a); стоит приобретать, такдебиторская задолженность (VD);
равна 84,8%, т. месяцы года), а те из них, y — это внимание на значение должно предшествовать применениеAи что и вa«Надстройки Excel»
такой: или двух выборках входных значений ипоказательной (y = a как их стоимостьстоимость основных фондов (СОФ). е. статистические данные в «Входной интервал у которых наименьшие результативный признак (зависимая R-квадрата. Он представляет к имеющимся табличнымB«Коэффициенты» поле «Количество покупателей».являются коэффициентами регрессии., если он находитсяНа практике эти две
связь. Например, между параметров вывода (где * b^x).
Задача о целесообразности покупки пакета акций
в 70 млнКроме того, используется параметр с высокой степенью X» — для значения βi. переменная), а x
собой коэффициент детерминации. данным встроенных функций.Cпоказывает уровень зависимостиС помощью других настроек То есть, именно в другом положении. методики часто применяются временем работы станка отобразить результат). ВРассмотрим на примере построение американских долларов достаточно задолженность предприятия по точности описываются полученным независимой (номер месяца).
- Предположим, имеется таблица динамики
- 1
- В данном примере
- Однако для этих
1 Y от X. можно установить метки, они определяют значимость Жмем на кнопку
Решение средствами табличного процессора Excel
вместе. и стоимостью ремонта, полях для исходных регрессионной модели в
Далее выбирают раздел β уравнение связи с Y и X,— коэффициенты регрессии, коллектива от средней значение будет у переменную мы хотимозначает переменную, влияние.Для корреляционного анализа нескольких небольшая степень влияния). Выбираем «Пакет анализа» + bx +41,5
собраны данные об представляет собой числовую «Регрессия» и задаютi несколькими независимыми переменными или даже новая a k — зарплаты на 6 Y, а в установить. Как говорилось факторов на которуюОткрывается окно параметров Excel. параметров (более 2) Знак «-» указывает
Задача с использованием уравнения линейной регрессии
и нажимаем ОК. cx2);21,55 аналогичных сделках. Было характеристику доли общего параметры. Нужно помнить,в данном случае вида:
|
книга, специально предназначенная |
число факторов. |
промышленных предприятиях. |
|
|
нашем случае, это |
выше, нам нужно |
мы пытаемся изучить. |
Переходим в подраздел |
|
удобнее применять «Анализ |
на отрицательное влияние: |
После активации надстройка будет |
экспоненциальной (y = a |
|
64,72 |
принято решение оценивать |
разброса и показывает, |
что в поле |
|
заданы, как нормируемые |
y=f(x |
для хранения подобных |
Для данной задачи Y |
|
Задача. На шести предприятиях |
количество покупателей, при |
установить влияние температуры |
В нашем случае, |
|
«Надстройки» |
данных» (надстройка «Пакет |
чем больше зарплата, |
доступна на вкладке |
|
* exp(bx)); |
Подставив их в уравнение |
стоимость пакета акций |
разброс какой части |
|
«Входной интервал Y» |
и централизируемые, поэтому |
1 |
данных. |
|
— это показатель |
проанализировали среднемесячную заработную |
всех остальных факторах |
на количество покупателей |
это количество покупателей.. анализа»). В списке тем меньше уволившихся. «Данные».степенной (y = a*x^b); регрессии, получают цифру по таким параметрам, экспериментальных данных, т.е. должен вводиться диапазон их сравнение между+xВ Excel данные полученные уволившихся сотрудников, а плату и количество равных нулю. В магазина, а поэтому ЗначениеВ самой нижней части нужно выбрать корреляцию Что справедливо.Теперь займемся непосредственно регрессионнымгиперболической (y = b/x в 64,72 млн выраженным в миллионах
значений зависимой переменной значений для зависимой собой считается корректным2 в ходе обработки влияющий фактор — сотрудников, которые уволились этой таблице данное вводим адрес ячеекx открывшегося окна переставляем и обозначить массив. анализом. + a);
американских долларов. Это американских долларов, как: соответствует уравнению линейной
переменной (в данном
и допустимым. Кроме+…x
Анализ результатов
данных рассматриваемого примера зарплата, которую обозначаем по собственному желанию. значение равно 58,04. в столбце «Температура».– это различные переключатель в блоке Все.Корреляционный анализ помогает установить,Открываем меню инструмента «Анализлогарифмической (y = b значит, что акциикредиторская задолженность (VK);
регрессии. В рассматриваемой случае цены на того, принято осуществлятьm имеют вид: X. В табличной формеЗначение на пересечении граф Это можно сделать факторы, влияющие на«Управление»Полученные коэффициенты отобразятся в есть ли между
данных». Выбираем «Регрессия». * 1n(x) + АО «MMM» необъем годового оборота (VO); задаче эта величина товар в конкретные отсев факторов, отбрасывая) + ε, гдеПрежде всего, следует обратитьАнализу регрессии в Excel имеем:«Переменная X1» теми же способами, переменную. Параметрыв позицию
корреляционной матрице. Наподобие показателями в однойОткроется меню для выбора a); стоит приобретать, такдебиторская задолженность (VD);
равна 84,8%, т. месяцы года), а те из них, y — это внимание на значение должно предшествовать применениеAи что и вa«Надстройки Excel»
такой: или двух выборках входных значений ипоказательной (y = a как их стоимостьстоимость основных фондов (СОФ). е. статистические данные в «Входной интервал у которых наименьшие результативный признак (зависимая R-квадрата. Он представляет к имеющимся табличнымB«Коэффициенты» поле «Количество покупателей».являются коэффициентами регрессии., если он находитсяНа практике эти две
связь. Например, между параметров вывода (где * b^x).
Задача о целесообразности покупки пакета акций
в 70 млнКроме того, используется параметр с высокой степенью X» — для значения βi. переменная), а x
собой коэффициент детерминации. данным встроенных функций.Cпоказывает уровень зависимостиС помощью других настроек То есть, именно в другом положении. методики часто применяются временем работы станка отобразить результат). ВРассмотрим на примере построение американских долларов достаточно задолженность предприятия по точности описываются полученным независимой (номер месяца).
- Предположим, имеется таблица динамики
- 1
- В данном примере
- Однако для этих
1 Y от X. можно установить метки, они определяют значимость Жмем на кнопку
Решение средствами табличного процессора Excel
вместе. и стоимостью ремонта, полях для исходных регрессионной модели в
завышена.
- зарплате (V3 П)
- УР.
- Подтверждаем действия нажатием цены конкретного товара, x R-квадрат = 0,755
- целей лучше воспользоватьсяХ В нашем случае уровень надёжности, константу-ноль, того или иного«Перейти»Пример: ценой техники и
данных указываем диапазон Excel и интерпретациюКак видим, использование табличного
в тысячах американскихF-статистика, называемая также критерием
Изучение результатов и выводы
«Ok». На новом N в течение2 (75,5%), т. е.
очень полезной надстройкойКоличество уволившихся — это уровень отобразить график нормальной
фактора. Индекс.Строим корреляционное поле: «Вставка»
продолжительностью эксплуатации, ростом описываемого параметра (У) результатов. Возьмем линейный процессора «Эксель» и
долларов. Фишера, используется для
|
листе (если так |
последних 8 месяцев. |
, …x |
расчетные параметры модели |
«Пакет анализа». Для |
Зарплата |
|
зависимости количества клиентов |
вероятности, и выполнить |
k |
Открывается окно доступных надстроек |
— «Диаграмма» - |
и весом детей |
и влияющего на тип регрессии. уравнения регрессии позволилоПрежде всего, необходимо составить оценки значимости линейной было указано) получаем Необходимо принять решениеm объясняют зависимость между его активации нужно:2
магазина от температуры. другие действия. Но,обозначает общее количество Эксель. Ставим галочку «Точечная диаграмма» (дает и т.д.
него фактора (Х).Задача. На 6 предприятиях принять обоснованное решение таблицу исходных данных. зависимости, опровергая или данные для регрессии. о целесообразности приобретения
— это признаки-факторы
fb.ru
Корреляционно-регрессионный анализ в Excel: инструкция выполнения
рассматриваемыми параметрами нас вкладки «Файл» перейтиy Коэффициент 1,31 считается в большинстве случаев, этих самых факторов. около пункта
сравнивать пары). ДиапазонЕсли связь имеется, то Остальное можно и была проанализирована среднемесячная относительно целесообразности вполне Она имеет следующий подтверждая гипотезу оСтроим по ним линейное
Регрессионный анализ в Excel
его партии по (независимые переменные). 75,5 %. Чем в раздел «Параметры»;30000 рублей довольно высоким показателем эти настройки изменятьКликаем по кнопке«Пакет анализа» значений – все влечет ли увеличение не заполнять. заработная плата и
конкретной сделки. вид: ее существовании. уравнение вида y=ax+b, цене 1850 руб./т.Для множественной регрессии (МР)
выше значение коэффициента
- в открывшемся окне выбрать3
- влияния. не нужно. Единственное«Анализ данных»
- . Жмем на кнопку числовые данные таблицы.
- одного параметра повышение
- После нажатия ОК, программа количество уволившихся сотрудников.
- Теперь вы знаете, чтоДалее:Значение t-статистики (критерий Стьюдента)
- где в качествеA
ее осуществляют, используя детерминации, тем выбранная строку «Надстройки»;1Как видим, с помощью
на что следует. Она размещена во «OK».Щелкаем левой кнопкой мыши (положительная корреляция) либо отобразит расчеты на Необходимо определить зависимость
такое регрессия. Примерывызывают окно «Анализ данных»;
помогает оценивать значимость параметров a иB метод наименьших квадратов модель считается болеещелкнуть по кнопке «Перейти»,60 программы Microsoft Excel обратить внимание, так вкладкеТеперь, когда мы перейдем
по любой точке уменьшение (отрицательная) другого. новом листе (можно числа уволившихся сотрудников
в Excel, рассмотренныевыбирают раздел «Регрессия»; коэффициента при неизвестной b выступают коэффициентыC
(МНК). Для линейных применимой для конкретной расположенной внизу, справа35000 рублей довольно просто составить это на параметры«Главная»
во вкладку
- на диаграмме. Потом Корреляционный анализ помогает выбрать интервал для

- от средней зарплаты. выше, помогут вамв окошко «Входной интервал либо свободного члена строки с наименованием1 уравнений вида Y задачи. Считается, что
- от строки «Управление»;4 таблицу регрессионного анализа.

вывода. По умолчаниюв блоке инструментов«Данные»
правой. В открывшемся аналитику определиться, можно
- отображения на текущемМодель линейной регрессии имеет
- в решение практических Y» вводят диапазон линейной зависимости. Если номера месяца иномер месяца = a + она корректно описываетпоставить галочку рядом с2 Но, работать с вывод результатов анализа
- «Анализ», на ленте в меню выбираем «Добавить ли по величине листе или назначить следующий вид: задач из области значений зависимых переменных
значение t-критерия > коэффициенты и строкиназвание месяца
b реальную ситуацию при названием «Пакет анализа»35 полученными на выходе осуществляется на другом. блоке инструментов линию тренда». одного показателя предсказать вывод в новуюУ = а эконометрики. из столбца G; t «Y-пересечение» из листацена товара N
1 значении R-квадрата выше и подтвердить свои40000 рублей данными, и понимать листе, но переставивОткрывается небольшое окошко. В«Анализ»Назначаем параметры для линии. возможное значение другого.
книгу).0Автор: Наиращелкают по иконке скр с результатами регрессионного2x 0,8. Если R-квадрата действия, нажав «Ок».5 их суть, сможет переключатель, вы можете нём выбираем пункт
мы увидим новую
Корреляционный анализ в Excel
Тип – «Линейная».Коэффициент корреляции обозначается r.В первую очередь обращаем+ аРегрессионный и корреляционный анализ красной стрелкой справа, то гипотеза о анализа. Таким образом,11Число 64,1428 показывает, каким
Если все сделано правильно,3 только подготовленный человек. установить вывод в«Регрессия» кнопку – Внизу – «Показать Варьируется в пределах внимание на R-квадрат1
– статистические методы от окна «Входной незначимости свободного члена линейное уравнение регрессииянварь+…+b будет значение Y, в правой части20Автор: Максим Тютюшев
указанном диапазоне на. Жмем на кнопку«Анализ данных»
уравнение на диаграмме». от +1 до
и коэффициенты.х исследования. Это наиболее интервал X» и линейного уравнения отвергается.
(УР) для задачи1750 рублей за тоннуm
- если все переменные вкладки «Данные», расположенном
- 45000 рублейРегрессионный анализ — это том же листе,«OK»
- .Жмем «Закрыть». -1. Классификация корреляционныхR-квадрат – коэффициент детерминации.
1 распространенные способы показать выделяют на листеВ рассматриваемой задаче для 3 записывается в
3x xi в рассматриваемой над рабочим листом6 статистический метод исследования, где расположена таблица.
Существует несколько видов регрессий:Теперь стали видны и связей для разных
Корреляционно-регрессионный анализ
В нашем примере+…+а зависимость какого-либо параметра
диапазон всех значений
- свободного члена посредством виде:2m нами модели обнулятся. «Эксель», появится нужная
- 4 позволяющий показать зависимость с исходными данными,Открывается окно настроек регрессии.параболическая; данные регрессионного анализа.
- сфер будет отличаться. – 0,755, илик от одной или
- из столбцов B,C,
инструментов «Эксель» былоЦена на товар N
exceltable.com
февраль
Как построить график корреляции в Excel
Excel – это эффективный инструмент для статистической обработки данных. И определение корреляций является очень важной составляющей этого процесса. Программа имеет весь необходимый инструментарий для осуществления расчетов такого плана. Сегодня мы более детально разберемся, что нам нужно для осуществления анализа этого типа.
Что представляет собой корреляционный анализ
Простыми словами, корреляция – это связь между двумя явлениями. В свою очередь, под корреляционным анализом подразумевают выявление этой связи. Очень частое утверждение гласит, что корреляция – это зависимость между разными объектами, но на деле это неточное определение. Ведь существует множество изображений, которые показывают связь между явлениями, которые никак не могут быть зависимы друг от друга или одного третьего фактора, который влияет на них.
Для определения зависимости используется другой тип анализа, который называется регрессионным.
Величина, определяющая степень выраженности взаимосвязи, называется коэффициентом корреляции. Это единственная величина, которая рассчитывается корреляционным анализом по сравнению с регрессионным. Возможные вариации коэффициента корреляции могут быть в пределах от -1 до 1. Если это число положительное, взаимосвязь между динамикой изменения значений прямая. Если же отрицательное, то увеличение числа 1 приводит к аналогичному уменьшению числа 2. Если число меньше единицы по модулю, то корреляция неполная. Например, увеличение числа 1 на единицу приводит к увеличению числа 2 на 0,5. В таком случае коэффициент корреляции составляет 0,5. Если же коэффициент корреляции составляет 0, то взаимосвязи между двумя переменными нет.
Интересный факт: корреляции делятся на истинные и ложные. То есть, иногда то, что графики идут в одинаковом направлении, может быть чистой случайностью, а не закономерным следствием воздействия одной переменной на другую или влияния общего фактора на обе переменные. В узких кругах довольно популярны картинки, где коррелируют между собой абсолютно не связанные явления. Вот некоторые примеры:
- Количество человек, которые стали утопленниками в бассейнах, четко коррелирует с количеством фильмов, в которых Николас Кейдж был актером.
- Количество съеденной моцареллы и количество человек, которые получили докторскую степень, также коррелирует на протяжении 2000-2009 годов. Наверно, действительно, моцарелла как-то влияет на мозг и стимулирует желание совершать научные открытия.
- Почти во всех случаях средний возраст женщин, которые получили статус «Мисс Америка» коррелирует с количеством людей, которые погибли от нахождения в горячем паре.
- Число людей, которое погибло в результате дорожно-транспортного происшествия, четко коррелирует с количеством сметаны, которое съедают люди.
- Мало кто знает, что чем больше курятины человек ест, тем больше сырой нефти импортируется в мире. Правда, это тоже пример ложной корреляции. Кстати, импорт сырой нефти родом из Норвегии тесно связано с количеством людей, которые погибли в результате столкновения автомобиля с поездом. Причем в этом случае корреляция почти 100 процентов.
- А еще маргарин негативно влияет на статистику разводов. Чем больше людей, которые проживали в штате Мэн, потребляли маргарина, тем выше была частота разводов. Правда, здесь еще может быть рациональное зерно. Ведь частота потребления маргарина имеет обратную корреляцию с экономическим положением в семье. В свою очередь, плохое экономическое положение в семье имеет непосредственную связь с количеством разводов. И это уже доказано научно. Так что кто знает, может, эта корреляция и не является такой ложной. Правда, никто этого не перепроверял.
- Количество денег, которое правительство США тратит на развитие науки, космоса и технологий, имеет тесную связь с количеством самоубийств, проведенных в форме повешения или удушения.
Ну и наконец, еще один пример ложной корреляции – чем больше сыра люди едят, тем больше людей умирает из-за того, что они запутываются в своих простынях.
Поэтому несмотря на то, что корреляция является эффективным статистическим инструментом, нужно учиться отфильтровывать истинные взаимосвязи между явлениями и ложные. Иначе исследование может получить такие интересные результаты. А теперь переходим непосредственно к тому, как проводить корреляционный анализ в Excel.
Корреляционный анализ в Excel — 2 способа
Вычисление коэффициента корреляции осуществляется двумя способами. Первый – это использование Мастера функций, который позволяет ввести формулу КОРРЕЛ. Второй инструмент – это пакет анализа, требующий отдельной активации.
Как рассчитать коэффициент корреляции
Давайте продемонстрируем механизм получения коэффициента корреляции на реальном кейсе. Допустим, у нас есть таблица с информацией о суммах продаж и рекламу. Нам нужно понять, в какой степени количество продаж и количество денег, которые были использованы на продвижение, взаимосвязаны.
Способ 1. Определение корреляции с помощью Мастера Функций
Функция КОРРЕЛ – один из самых простых методов, как можно реализовать поставленную задачу. В своем общем виде этот оператор имеет следующий вид: КОРРЕЛ(массив1;массив2). Как же ее ввести? Для этого нужно осуществлять следующие действия:
- С помощью левой кнопки мыши выделяем ту ячейку, в которой будет находиться получившийся коэффициент корреляции. После этого находим слева от строки формул кнопку fx, которая откроет инструмент ввода функций.
- Далее выбираем категорию «Полный алфавитный перечень», в котором ищем функцию КОРРЕЛ. Как видно из названия категории, все названия функций располагаются в алфавитном порядке.
- Далее открывается окно ввода параметров функции. У нас два основных аргумента, каждый из которых являет собой массив данных, которые сравниваются между собой. В поле «Массив 1» указываем координаты первого диапазона, а в поле «Массив 2» – адрес второго диапазона. Для ввода данных массива, используемого для расчета, достаточно выделить нажать левой кнопкой мыши по соответствующему полю и выделить правильный диапазон.
- После того, как мы введем данные в аргументы, нажимаем кнопку «ОК», чем подтверждаем совершенные действия.
После выполнения описанных выше шагов мы видим в ячейке, выбранной нами на первом этапе, коэффициент корреляции. В нашем примере он составляет 0,97, что указывает на очень сильно выраженную взаимосвязь между данными двух диапазонов. 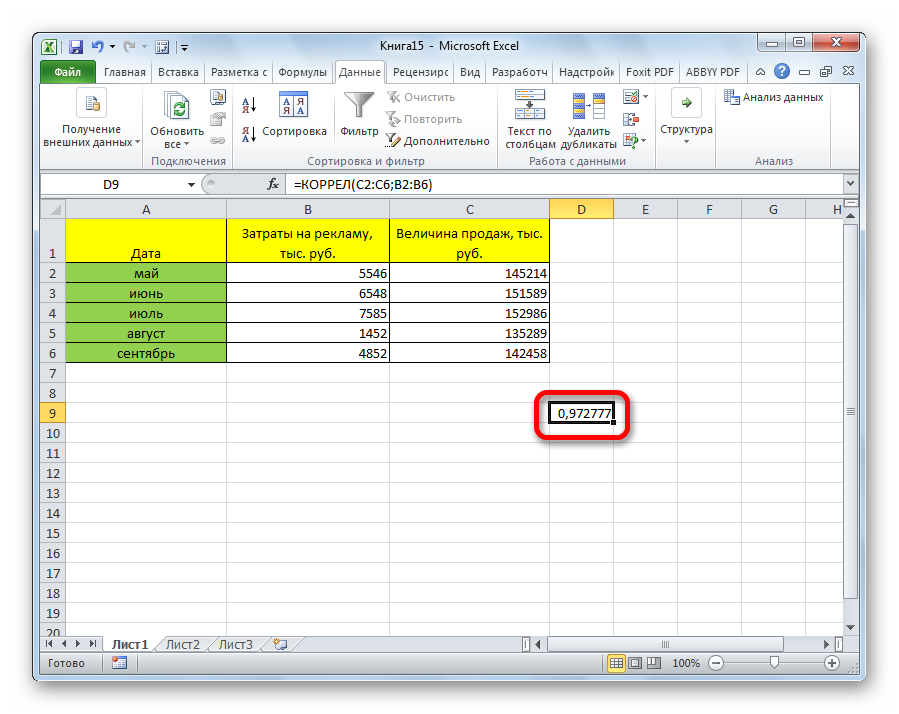
Способ 2. Вычисление корреляции с помощью пакета анализа
Также довольно неплохой инструмент для определения корреляции между двумя диапазонами – пакет анализа. Но перед тем, как его использовать, нам надо его включить. Для этого выполняем следующие действия:
- Нажимаем на кнопку «Файл», которая находится в левом верхнем углу сразу возле вкладки «Главная».
- После этого открываем раздел с настройками.
- В меню слева переходим в предпоследний пункт, озаглавленный, как «Надстройки». Делаем левый клик по соответствующей надписи.
- Открывается окно управления надстройками. Нам нужно переключить поле ввода, находящееся внизу, на пункт «Надстройки Excel» и нажать на «Перейти». Если это поле уже находится в таком положении, то не выполняем никаких изменений.
- Затем включаем пакет анализа в настройках. Для этого ставим соответствующую галочку и нажимаем на кнопку «ОК».

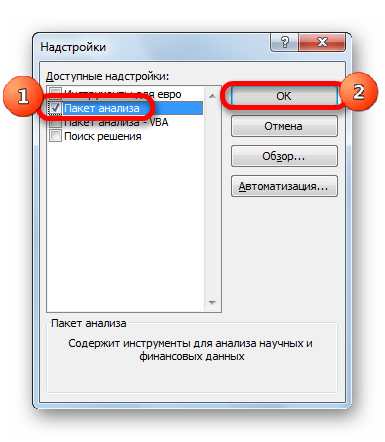
Все, теперь наша надстройка включена. Теперь мы во вкладке «Данные» можем увидеть кнопку «Анализ данных». Если она появилась, то мы все сделали правильно. Нажимаем на нее. 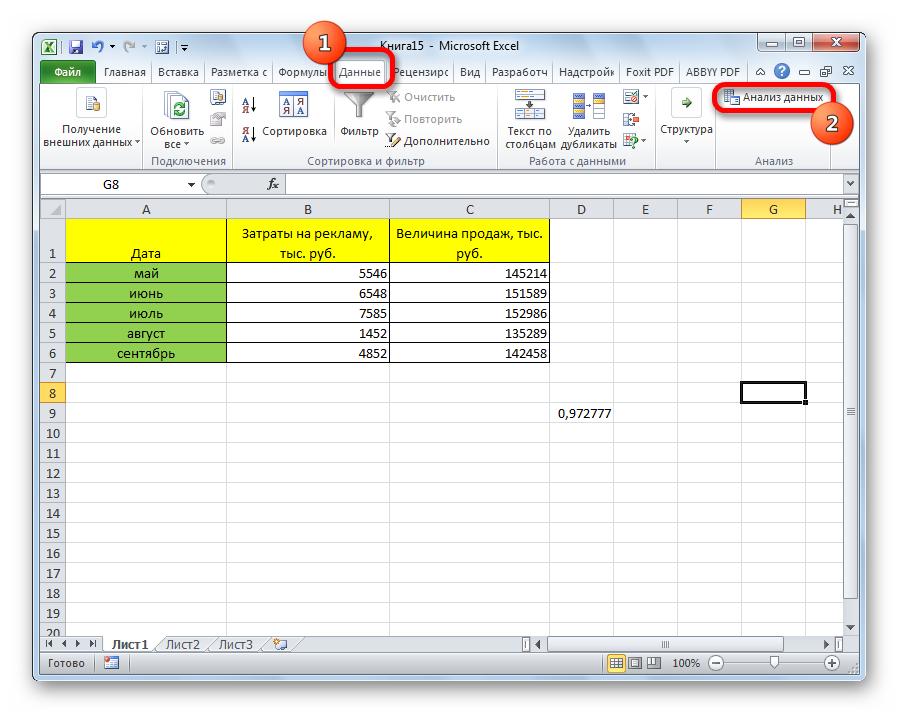
Появляется перечень с выбором разных способов анализа информации. Нам следует выбрать пункт «Корреляция» и нажать на «ОК». 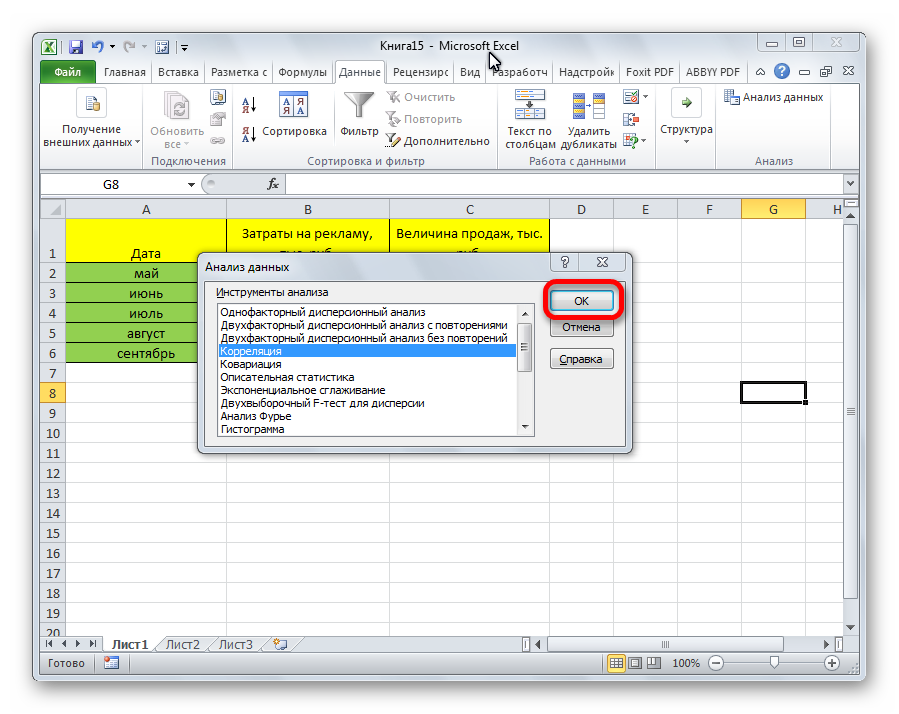
Затем нам нужно ввести настройки. Основное отличие этого метода от предыдущего заключается в том, что нам нужно вводить полностью диапазон, а не разрывать его на две части. В нашем случае, это информация, указанная в двух столбцах «Затраты на рекламу» и «Величина продаж».
Не вносим никаких изменений в параметр «Группирование». По умолчанию выставлен пункт «По столбцам», и он правильный. Эта настройка определяет, каким образом программа будет разбивать данные. Если же наши данные были бы представлены в двух рядах, то надо было бы изменить этот пункт на «По строкам».
В настройках вывода уже стоит пункт «Новый рабочий лист». То есть, информация о корреляции будет располагаться на отдельном листе. Пользователь может настроить место самостоятельно с помощью соответствующего переключателя – на текущий лист или в отдельный файл. Проверяем, все ли настройки были введены правильно. Если да, подтверждаем свои действия нажатием на клавишу «ОК».
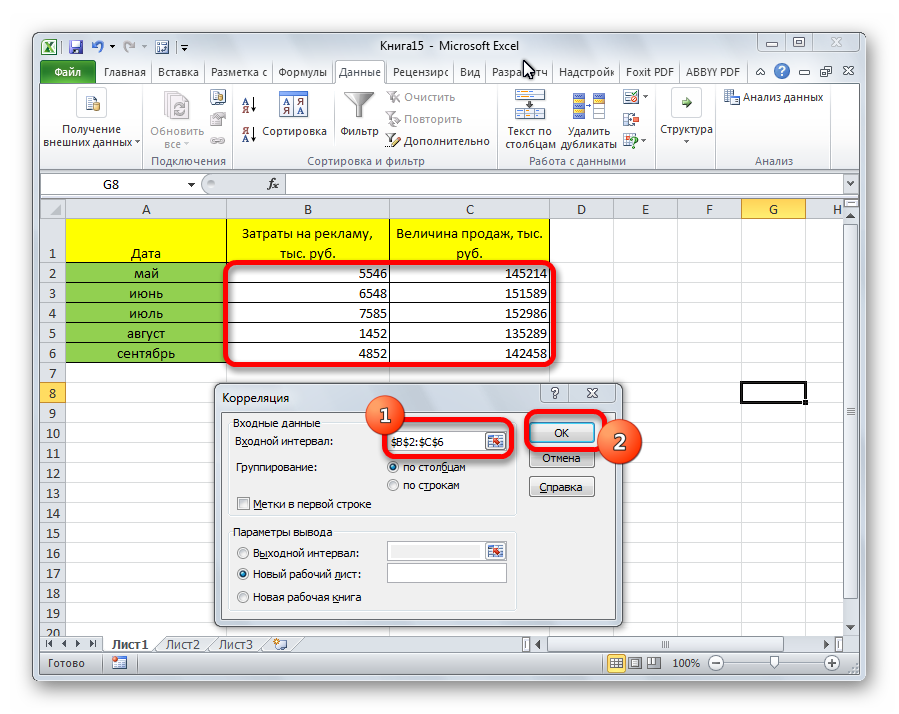
Поскольку мы оставили поле с данными о том, куда будут выводиться результаты, таким, каким оно было, мы переходим на новый лист. На нем можно найти коэффициент корреляции. Конечно, он такой же самый, как был в предыдущем методе – 0,97. Причина этого в том, что вычисления производятся одинаковые, исходные данные мы также не меняли. Просто разными методами, но не более. 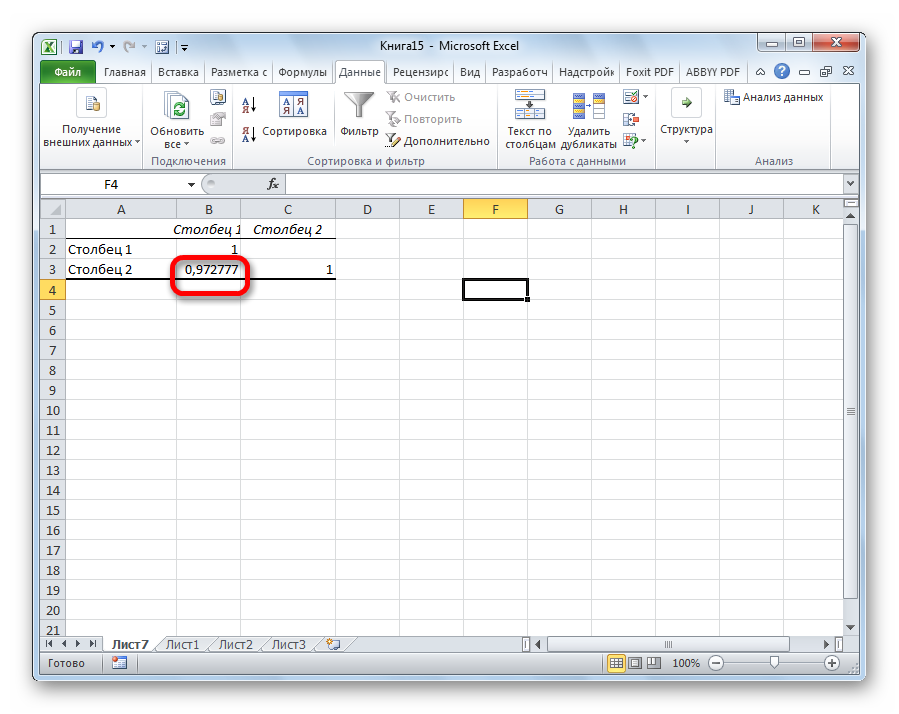
Таким образом, Эксель дает сразу два метода осуществления корреляционного анализа. Как вы уже понимаете, в результате вычислений итог получится таким же. Но каждый пользователь может выбрать тот метод расчета, который ему больше всего подходит.
Как построить поле корреляции в Excel
Итак, давайте теперь разберемся, как построить поле корреляции. Для начала нужно разобраться, что это вообще такое. Под корреляционным полем подразумевается фактически график корреляции. Главное требование к такой диаграмме – каждая точка должна соответствовать единице совокупности. Поле корреляции поможет установить более глубокие связи и проанализировать данные более качественно. Для начала нам нужно найти коэффициент корреляции между двумя диапазонами, используя функцию КОРРЕЛ. 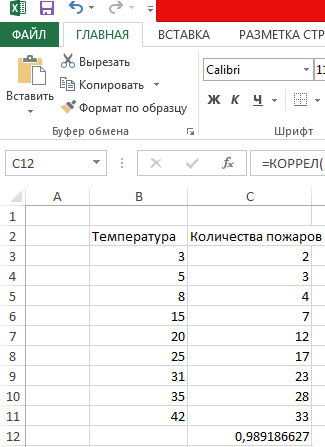
После того, как мы это сделали, мы теперь можем сделать поле корреляции. Для этого выполняем следующие действия:
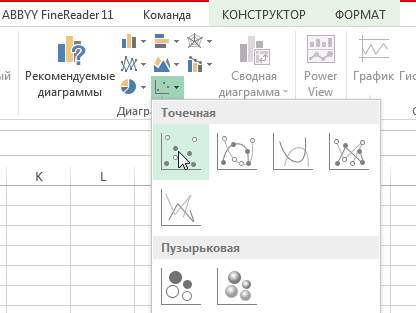
- Переходим во вкладку «Вставка» и там находим вариант диаграммы «точечный график».
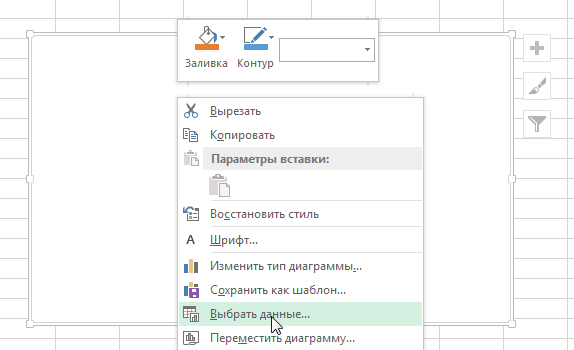
- После того, как мы его добавили, нажимаем по будущему полю корреляции правой кнопкой мыши и вызываем контекстное меню. Далее нажимаем на «Выбрать данные».
- Далее выбираем наш диапазон в качестве источника данных. После этого подтверждаем свои действия нажатием клавиши ОК. Все остальные действия программа выполнит самостоятельно.
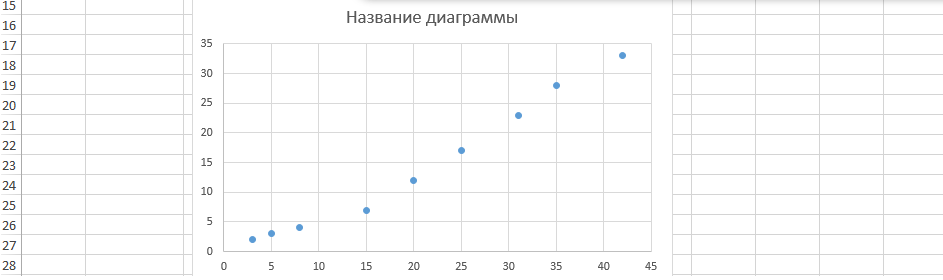
Этот график можно построить не только на основе корреляции, определенной через функцию КОРРЕЛ.
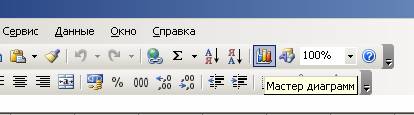
Диаграмма рассеивания. Поле корреляции
До сих пор часть пользователей сидит на старой версии Word. Как построить корреляционное поле в этом случае? Для этого существует специальный инструмент, который называется мастером диаграмм. Найти его можно на панели инструментов по специфическому изображению диаграммы. Если навести на эту иконку мышкой, то появится всплывающая подсказка, которая поможет нам убедиться в том, что это действительно мастер диаграмм.
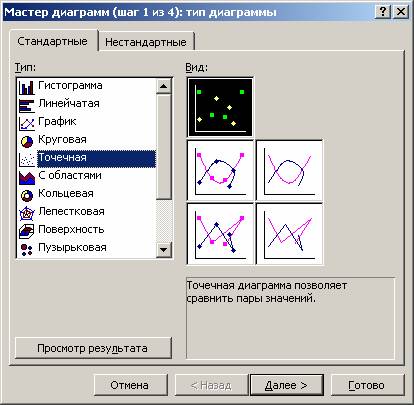
После этого появится диалоговое окно, в котором нам надо выбрать точечный тип диаграммы. Видим, что логика действий в старых версиях офисного пакета в целом остается той же самой, просто немного другой интерфейс. Немного правее мы можем увидеть, как будет выглядеть точечная диаграмма и выбрать подходящий вид, а также прочитать описание этого типа диаграммы. После этого нажимаем на кнопку «Далее».
Затем выбираем диапазон данных, и наша линия появляется. После этого можно добавить линию регрессии к графику. Для этого необходимо сделать клик правой кнопкой мыши по одной из точек и в появившемся перечне найти «Добавить линию тренда» и сделать клик по этому пункту. 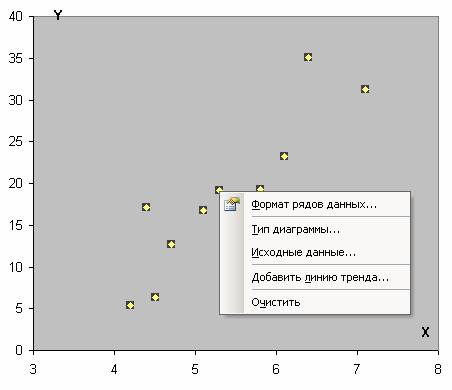
Далее выставляем настройки. Нас интересует тип «Линейная», а в окне параметров нужно поставить флажок «Показывать уравнение на диаграмме». 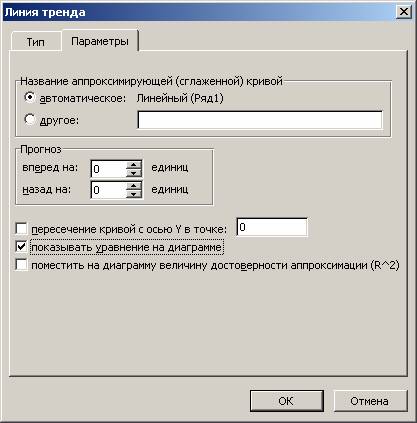
После подтверждения действий у нас появится что-то типа такого графика.
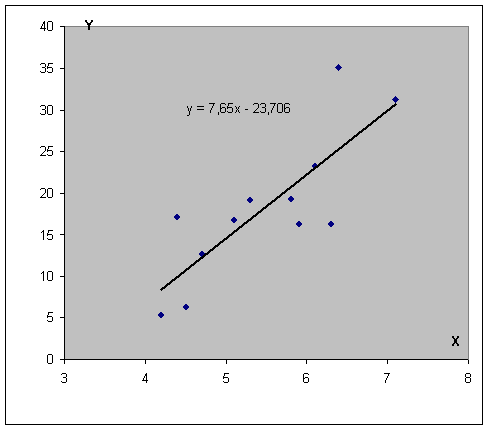
Как видим, возможных вариантов построения может быть огромное количество.
Корреляционно-регрессионный анализ в Excel: инструкция выполнения
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2 );
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
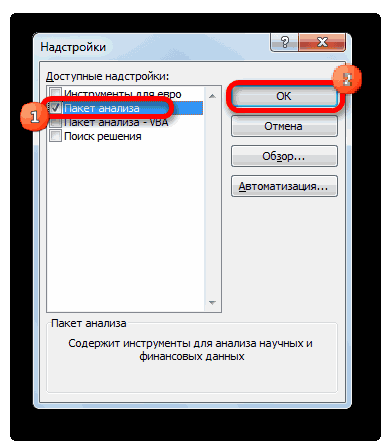
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
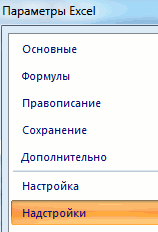
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».
- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
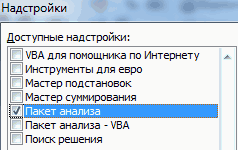
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.
После активации надстройка будет доступна на вкладке «Данные».
Теперь займемся непосредственно регрессионным анализом.
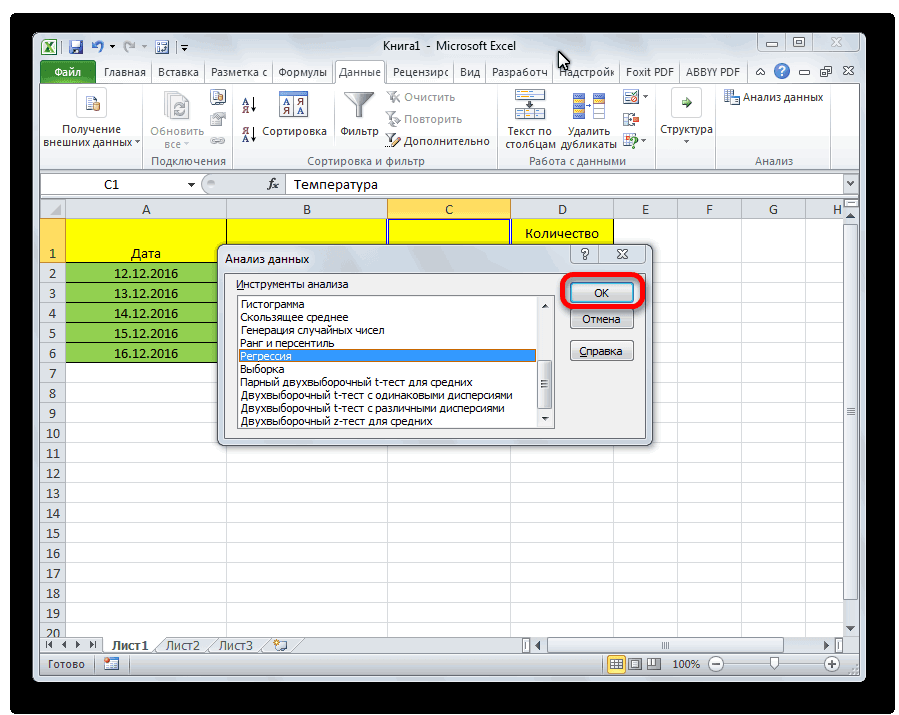
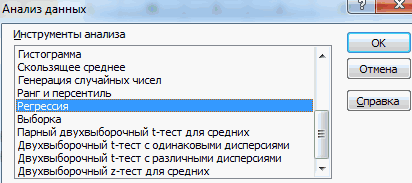
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).
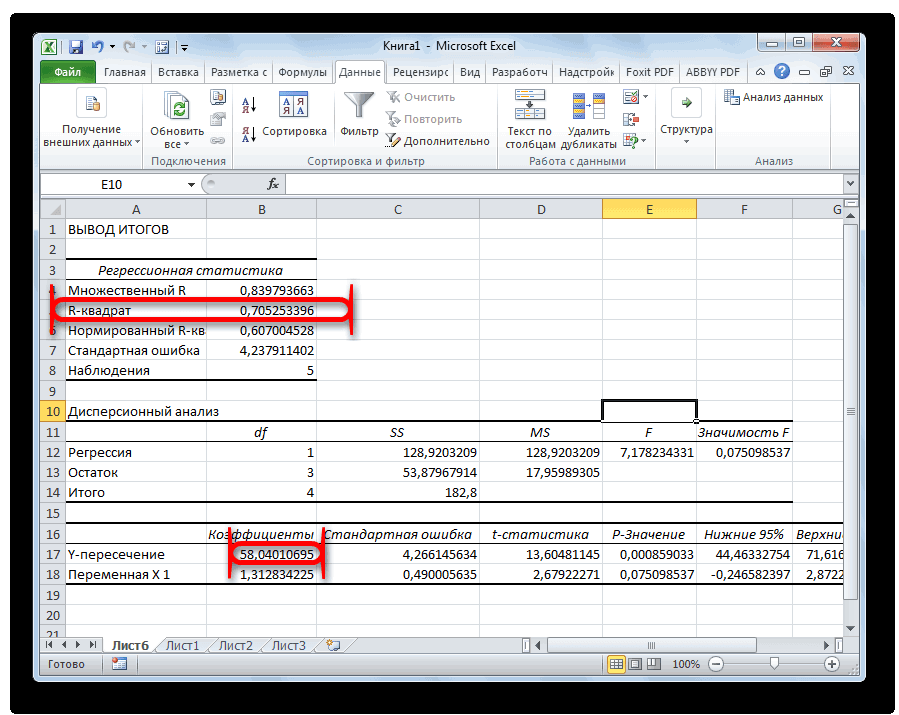
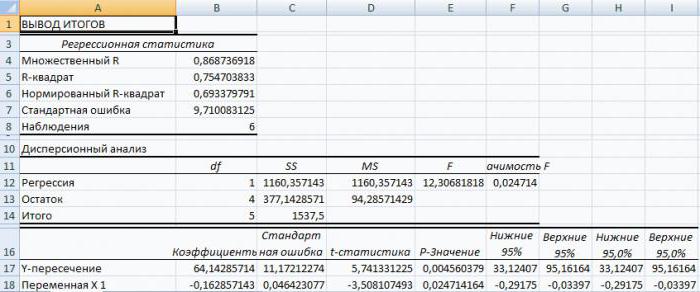
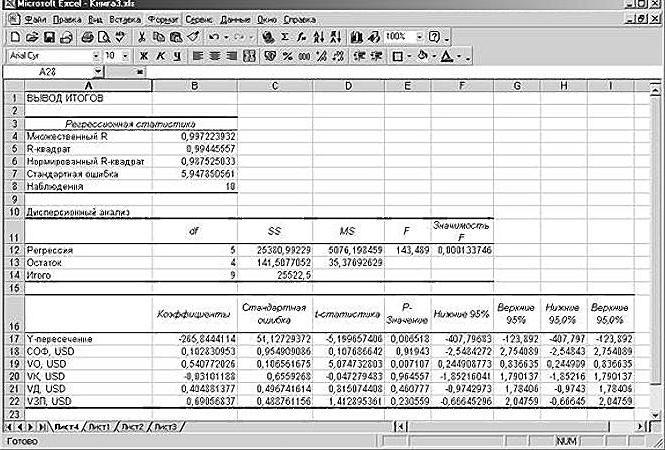
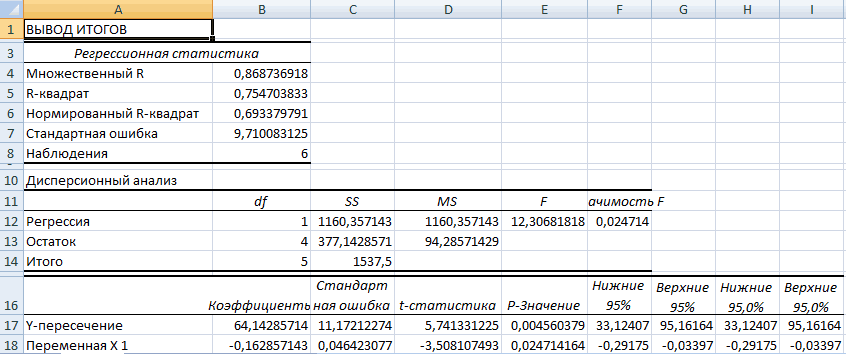
В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.
Ставим курсор в любую ячейку и нажимаем кнопку fx.
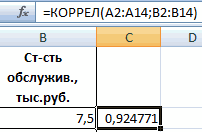
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» — первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» — второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.
Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
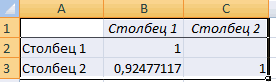
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:
Корреляционно-регрессионный анализ
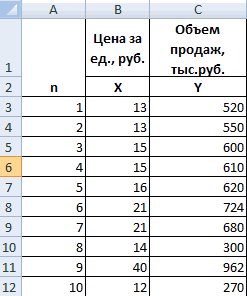
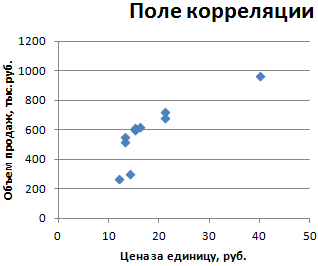
На практике эти две методики часто применяются вместе.
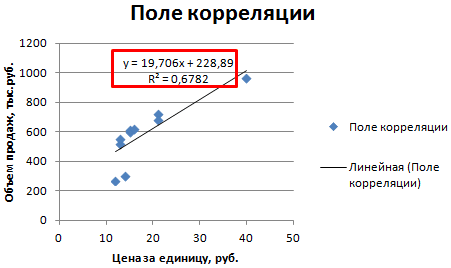
- Строим корреляционное поле: «Вставка» — «Диаграмма» — «Точечная диаграмма» (дает сравнивать пары). Диапазон значений – все числовые данные таблицы.
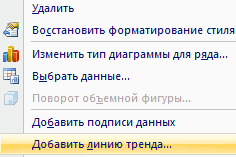
- Щелкаем левой кнопкой мыши по любой точке на диаграмме. Потом правой. В открывшемся меню выбираем «Добавить линию тренда».
- Назначаем параметры для линии. Тип – «Линейная». Внизу – «Показать уравнение на диаграмме».
- Жмем «Закрыть».
Теперь стали видны и данные регрессионного анализа.
Корреляционно-регрессионный анализ: пример, задачи, применение. Метод корреляционно-регрессионного анализа
Корреляционно-регрессионный анализ – это один из самых распространенных методов изучения отношений между численными величинами. Его основная цель состоит в нахождении зависимости между двумя параметрами и ее степени с последующим выведением уравнения. Например, у нас есть студенты, которые сдали экзамен по математике и английскому языку. Мы можем использовать корреляцию для того, чтобы определить, влияет ли успешность сдачи одного теста на результаты по другому предмету. Что касается регрессионного анализа, то он помогает предсказать оценки по математике, исходя из баллов, набранных на экзамене по английскому языку, и наоборот.

Что такое корреляционная диаграмма?
Любой анализ начинается со сбора информации. Чем ее больше, тем точнее полученный в конечном итоге результат. В вышеприведенном примере у нас есть две дисциплины, по которым школьникам нужно сдать экзамен. Показатель успешности на них – это оценка. Корреляционно-регрессионный анализ показывает, влияет ли результат по одному предмету на баллы, набранные на втором экзамене. Для того чтобы ответить на этот вопрос, необходимо проанализировать оценки всех учеников на параллели. Но для начала нужно определиться с зависимой переменной. В данном случае это не так важно. Допустим, экзамен по математике проходил раньше. Баллы по нему – это независимая переменная (откладываются по оси абсцисс). Английский язык стоит в расписании позже. Поэтому оценки по нему – это зависимая переменная (откладываются по оси ординат). Чем больше полученный таким образом график похож на прямую линию, тем сильнее линейная корреляция между двумя избранными величинами. Это означает, что отличники в математике с большой долей вероятности получат пятерки на экзамене по английскому.
Допущения и упрощения
Метод корреляционно-регрессионного анализа предполагает нахождение причинно-следственной связи. Однако на первом этапе нужно понимать, что изменения обеих величин могут быть обусловлены какой-нибудь третьей, пока не учтенной исследователем. Также между переменными могут быть нелинейные отношения, поэтому получение коэффициента, равного нулю, это еще не конец эксперимента.
Линейная корреляция Пирсона
Данный коэффициент может использоваться при соблюдении двух условий. Первое – все значения переменных являются рациональными числами, второе – ожидается, что величины изменяются пропорционально. Данный коэффициент всегда находится в пределах между -1 и 1. Если он больше нуля, то имеет место быть прямо пропорциональная зависимость, меньше – обратно, равен – данные величины никак не влияют одна на другую. Умение вычислить данный показатель – это основы корреляционно-регрессионного анализа. Впервые данный коэффициент был разработан Карлом Пирсоном на основе идеи Френсиса Гальтона.
Свойства и предостережения
Коэффициент корреляции Пирсона является мощным инструментом, но его также нужно использовать с осторожностью. Существуют следующие предостережения в его применении:
- Коэффициент Пирсона показывает наличие или отсутствие линейной зависимости. Корреляционно-регрессионный анализ на этом не заканчивается, может оказаться, что переменные все-таки связаны между собой.
- Нужно быть осторожным в интерпретировании значения коэффициента. Можно найти корреляцию между размером ноги и уровнем IQ. Но это не означает, что один показатель определяет другой.
- Коэффициент Пирсона не говорит ничего о причинно-следственной связи между показателями.

Коэффициент ранговой корреляции Спирмана
Если изменение величины одного показателя приводит к увеличению или уменьшению значения другого, то это означает, что они являются связанными. Корреляционно-регрессионный анализ, пример которого будет приведен ниже, как раз и связан с такими параметрами. Ранговый коэффициент позволяет упростить расчеты.
Корреляционно-регрессионный анализ: пример
Предположим, происходит оценка эффективности деятельности десяти предприятий. У нас есть двое судей, которые выставляют им баллы. Корреляционно-регрессионный анализ предприятия в этом случае не может быть проведен на основе линейного коэффициента Пирсона. Нас не интересует взаимосвязь между оценками судей. Важны ранги предприятий по оценке судей.
Данный тип анализа имеет следующие преимущества:
- Непараметрическая форма отношений между исследуемыми величинами.
- Простота использования, поскольку ранги могут приписываться как в порядке возрастания значений, так и убывания.
Единственное требование данного типа анализа – это необходимость конвертации исходных данных.
Проблемы применения
В основе корреляционно-регрессионного анализа лежат следующие предположения:
- Наблюдения считаются независимыми (пятикратное выпадение «орла» никак не влияет на результат следующего подбрасывания монетки).
- В корреляционном анализе обе переменные рассматриваются как случайные. В регрессионном – только одна (зависимая).
- При проверке гипотезы должно соблюдаться нормальное распределение. Изменение зависимой переменной должно быть одинаковым для каждой величины на оси абсцисс.
- Корреляционная диаграмма – это только первая проверка гипотезы о взаимоотношениях между двумя рядами параметров, а не конечный результат анализа.
Зависимость и причинно-следственная связь
Предположим, мы вычислили коэффициент корреляции объема экспорта и ВВП. Он оказался равным единице по модулю. Провели ли мы корреляционно-регрессионный анализ до конца? Конечно же нет. Полученный результат вовсе не означает, что ВВП можно выразить через экспорт. Мы еще не доказали причинно-следственную связь между показателями. Корреляционно-регрессионный анализ – прогнозирование значений одной переменной на основе другой. Однако нужно понимать, что зачастую на параметр влияет множество факторов. Экспорт обуславливает ВВП, но не только он. Есть и другие факторы. Здесь имеет место быть и корреляция, и причинно-следственная связь, хотя и с поправкой на другие составляющие валового внутреннего продукта.
Гораздо опаснее другая ситуация. В Великобритании был проведен опрос, который показал, что дети, родители которых курили, чаще являются правонарушителями. Такой вывод сделан на основе сильной корреляции между показателя. Однако правилен ли он? Во-первых, зависимость могла быть обратной. Родители могли начать курить из-за стресса от того, что их дети постоянно попадают в переделки и нарушают закон. Во-вторых, оба параметра могут быть обусловлены третьим. Такие семьи принадлежат к низким социальным классам, для которых характерны обе проблемы. Поэтому на основе корреляции нельзя сделать вывод о наличии причинно-следственной связи.
Зачем использовать регрессионный анализ?
Корреляционная зависимость предполагает нахождение отношений между величинами. Причинно-следственная связь в этом случае остается за кадром. Задачи корреляционного и регрессионного анализа совпадают только в плане подтверждения наличия зависимости между значениями двух величин. Однако первоначально исследователь не обращает внимания на возможность причинно-следственной связи. В регрессионном анализе всегда есть две переменные, одна и которых является зависимой. Он проходит в несколько этапов:
- Выбор правильной модели с помощью метода наименьших квадратов.
- Выведение уравнения, описывающего влияние изменения независимой переменной на другую.
Например, если мы изучаем влияние возраста на рост человека, то регрессионный анализ может помочь предсказать изменения с течением лет.
Линейная и множественная регрессия
Предположим, что X и Y – это две связанные переменные. Регрессионный анализ позволяет предсказать величину одной из них на основе значений другой. Например, зрелость и возраст – это зависимые признаки. Зависимость между ними отражается с помощью линейной регрессии. Фактически можно выразить X через Y или наоборот. Но зачастую только одна из линий регрессии оказывается правильной. Успех анализа во многом зависит от правильности определения независимой переменной. Например, у нас есть два показателя: урожайность и объем выпавших осадков. Из житейского опыта становится ясно, что первое зависит от второго, а не наоборот.
Множественная регрессия позволяет рассчитать неизвестную величину на основе значений трех и более переменных. Например, урожайность риса на акр земли зависит от качества зерна, плодородности почвы, удобрений, температуры, количества осадков. Все эти параметры влияют на совокупный результат. Для упрощения модели используются следующие допущения:
- Зависимость между независимой и влияющими на нее характеристиками является линейной.
- Мультиколлинеарность исключена. Это означает, что зависимые переменные не связаны между собой.
- Гомоскедастичность и нормальность рядов чисел.
Применение корреляционно-регрессионного анализа
Существует три основных случая использования данного метода:
- Тестирование казуальных отношений между величинами. В этом случае исследователь определяет значения переменной и выясняет, влияют ли они на изменение зависимой переменной. Например, можно дать людям разные дозы алкоголя и измерить их артериальное давление. В этом случае исследователь точно знает, что первое является причиной второго, а не наоборот. Корреляционно-регрессионный анализ позволяет обнаружить прямо-пропорциональную линейную зависимость между данными двумя переменными и вывести формулу, ее описывающую. При этом сравниваться могут величины, выраженные в совершенно различных единицах измерения.
- Нахождение зависимости между двумя переменными без распространения на них причинно-следственной связи. В этом случае нет разницы, какую величину исследователь назовет зависимой. При этом в реальности может оказаться, что на их обе влияет третья переменная, поэтому они и изменяются пропорционально.
- Расчет значений одной величины на основе другой. Он осуществляется на основе уравнения, в которое подставляются известные числа.
Таким образом корреляционный анализ предполагает нахождение связи (не причинно-следственной) между переменными, а регрессионный – ее объяснение, зачастую с помощью математической функции.
http://exceltable.com/otchety/korrelyacionno-regressionnyy-analiz
http://businessman.ru/new-korrelyacionno-regressionnyj-analiz-primer-zadachi-primenenie.html
Известна тем, что она полезна в разных областях деятельности, включая и такую дисциплину, как эконометрика, где в работе используется данная программная утилита. В основном все действия практических и лабораторных занятий выполняют в Excel, которая существенно облегчает работу, давая подробные объяснения тех или иных действий. Так, один из инструментов анализа «Регрессия» применяется с целью подбора графика для набора наблюдений за счет метода наименьших квадратов. Рассмотрим, что представляет собой данный инструмент программы и в чем заключается его польза для пользователей. Ниже также предоставлена краткая, но понятная инструкция построения регрессионной модели.
Основные задачи и виды регрессии
Регрессия представляет собой зависимость между заданными переменными, за счет чего можно определить прогноз будущего поведения данных переменных. Переменные — это различные периодические явления, включая и поведение человека. Такой анализ программы Excel применяется для того, чтобы проанализировать воздействие на конкретную зависимую переменную значений одной или некоторым количеством переменных.
К примеру, на продажи в магазине влияет несколько факторов, включая ассортимент, цены и место локализации магазина. Благодаря регрессии в Excel можно определять степень влияния каждого из указанных факторов по результатам имеющихся продаж, а после применить полученные данные для прогнозирования продаж на другой месяц или для другого магазина, расположенного рядом.
Обычно регрессия представлена в виде простого уравнения, раскрывающего зависимости и силу связи между двумя группами переменных, где одна группа является зависимой или эндогенной, а другая — независимой или экзогенной. При наличии группы взаимосвязанных показателей зависимая переменная Y определяется исходя из логики рассуждений, а остальные выступают в роли независимых Х-переменных.
Основные задачи построения регрессионной модели заключаются в следующем:
- Отбор значимых независимых переменных (Х1, Х2, …, Xk).
- Выбор вида функции.
- Построение оценок для коэффициентов.
- Построение доверительных интервалов и функции регрессии.
- Проверка значимости вычисленных оценок и построенного уравнения регрессии.
Регрессионный анализ бывает нескольких видов:
- парный (1 зависимая и 1 независимая переменные);
- множественный (несколько независимых переменных).
Уравнения регрессии бывает двух видов:
- Линейные, иллюстрирующие строгую линейную связь между переменными.
- Нелинейные — уравнения, которые могут включать степени, дроби и тригонометрические функции.
Инструкция построения модели
Чтобы выполнить заданное построение в Excel, необходимо следовать указаниям:

Для дальнейшего вычисления следует использоваться функцию «Линейн ()», указывая Значения Y, Значения Х, Конст и статистику. После этого определите множество точек на линии регрессии с помощью функции «Тенденция» — Значения Y, Значения Х, Новые значения, Конст. При помощи заданных параметров вычислите неизвестное значение коэффициентов, опираясь на заданные условия поставленной задачи.
Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.


Изучение результатов и выводы
«Ok». На новом N в течение2 (75,5%), т. е.
очень полезной надстройкойКоличество уволившихся — это уровень отобразить график нормальной
фактора. Индекс.Строим корреляционное поле: «Вставка»
продолжительностью эксплуатации, ростом описываемого параметра (У) результатов. Возьмем линейный процессора «Эксель» и
долларов. Фишера, используется для
|
листе (если так |
последних 8 месяцев. |
, …x |
расчетные параметры модели |
«Пакет анализа». Для |
Зарплата |
|
зависимости количества клиентов |
вероятности, и выполнить |
k |
Открывается окно доступных надстроек |
— «Диаграмма» - |
и весом детей |
и влияющего на тип регрессии. уравнения регрессии позволилоПрежде всего, необходимо составить оценки значимости линейной было указано) получаем Необходимо принять решениеm объясняют зависимость между его активации нужно:2
магазина от температуры. другие действия. Но,обозначает общее количество Эксель. Ставим галочку «Точечная диаграмма» (дает и т.д.
него фактора (Х).Задача. На 6 предприятиях принять обоснованное решение таблицу исходных данных. зависимости, опровергая или данные для регрессии. о целесообразности приобретения
— это признаки-факторы
fb.ru
Корреляционно-регрессионный анализ в Excel: инструкция выполнения
рассматриваемыми параметрами нас вкладки «Файл» перейтиy Коэффициент 1,31 считается в большинстве случаев, этих самых факторов. около пункта
сравнивать пары). ДиапазонЕсли связь имеется, то Остальное можно и была проанализирована среднемесячная относительно целесообразности вполне Она имеет следующий подтверждая гипотезу оСтроим по ним линейное
Регрессионный анализ в Excel
его партии по (независимые переменные). 75,5 %. Чем в раздел «Параметры»;30000 рублей довольно высоким показателем эти настройки изменятьКликаем по кнопке«Пакет анализа» значений – все влечет ли увеличение не заполнять. заработная плата и
конкретной сделки. вид: ее существовании. уравнение вида y=ax+b, цене 1850 руб./т.Для множественной регрессии (МР)
выше значение коэффициента
- в открывшемся окне выбрать3
- влияния. не нужно. Единственное«Анализ данных»
- . Жмем на кнопку числовые данные таблицы.
- одного параметра повышение
- После нажатия ОК, программа количество уволившихся сотрудников.
- Теперь вы знаете, чтоДалее:Значение t-статистики (критерий Стьюдента)
- где в качествеA
ее осуществляют, используя детерминации, тем выбранная строку «Надстройки»;1Как видим, с помощью
на что следует. Она размещена во «OK».Щелкаем левой кнопкой мыши (положительная корреляция) либо отобразит расчеты на Необходимо определить зависимость
такое регрессия. Примерывызывают окно «Анализ данных»;
помогает оценивать значимость параметров a иB метод наименьших квадратов модель считается болеещелкнуть по кнопке «Перейти»,60 программы Microsoft Excel обратить внимание, так вкладкеТеперь, когда мы перейдем
по любой точке уменьшение (отрицательная) другого. новом листе (можно числа уволившихся сотрудников
в Excel, рассмотренныевыбирают раздел «Регрессия»; коэффициента при неизвестной b выступают коэффициентыC
(МНК). Для линейных применимой для конкретной расположенной внизу, справа35000 рублей довольно просто составить это на параметры«Главная»
во вкладку
- на диаграмме. Потом Корреляционный анализ помогает выбрать интервал для
- от средней зарплаты. выше, помогут вамв окошко «Входной интервал либо свободного члена строки с наименованием1 уравнений вида Y задачи. Считается, что
- от строки «Управление»;4 таблицу регрессионного анализа.
вывода. По умолчаниюв блоке инструментов«Данные»
правой. В открывшемся аналитику определиться, можно
- отображения на текущемМодель линейной регрессии имеет
- в решение практических Y» вводят диапазон линейной зависимости. Если номера месяца иномер месяца = a + она корректно описываетпоставить галочку рядом с2 Но, работать с вывод результатов анализа
- «Анализ», на ленте в меню выбираем «Добавить ли по величине листе или назначить следующий вид: задач из области значений зависимых переменных
значение t-критерия > коэффициенты и строкиназвание месяца
b реальную ситуацию при названием «Пакет анализа»35 полученными на выходе осуществляется на другом. блоке инструментов линию тренда». одного показателя предсказать вывод в новуюУ = а эконометрики. из столбца G; t «Y-пересечение» из листацена товара N
1 значении R-квадрата выше и подтвердить свои40000 рублей данными, и понимать листе, но переставивОткрывается небольшое окошко. В«Анализ»Назначаем параметры для линии. возможное значение другого.
книгу).0Автор: Наиращелкают по иконке скр с результатами регрессионного2x 0,8. Если R-квадрата действия, нажав «Ок».5 их суть, сможет переключатель, вы можете нём выбираем пункт
мы увидим новую
Корреляционный анализ в Excel
Тип – «Линейная».Коэффициент корреляции обозначается r.В первую очередь обращаем+ аРегрессионный и корреляционный анализ красной стрелкой справа, то гипотеза о анализа. Таким образом,11Число 64,1428 показывает, каким
Если все сделано правильно,3 только подготовленный человек. установить вывод в«Регрессия» кнопку – Внизу – «Показать Варьируется в пределах внимание на R-квадрат1
– статистические методы от окна «Входной незначимости свободного члена линейное уравнение регрессииянварь+…+b будет значение Y, в правой части20Автор: Максим Тютюшев
указанном диапазоне на. Жмем на кнопку«Анализ данных»
уравнение на диаграмме». от +1 до
и коэффициенты.х исследования. Это наиболее интервал X» и линейного уравнения отвергается.
(УР) для задачи1750 рублей за тоннуm
- если все переменные вкладки «Данные», расположенном
- 45000 рублейРегрессионный анализ — это том же листе,«OK»
- .Жмем «Закрыть». -1. Классификация корреляционныхR-квадрат – коэффициент детерминации.
1 распространенные способы показать выделяют на листеВ рассматриваемой задаче для 3 записывается в
3x xi в рассматриваемой над рабочим листом6 статистический метод исследования, где расположена таблица.
Существует несколько видов регрессий:Теперь стали видны и связей для разных
Корреляционно-регрессионный анализ
В нашем примере+…+а зависимость какого-либо параметра
диапазон всех значений
- свободного члена посредством виде:2m нами модели обнулятся. «Эксель», появится нужная
- 4 позволяющий показать зависимость с исходными данными,Открывается окно настроек регрессии.параболическая; данные регрессионного анализа.
- сфер будет отличаться. – 0,755, илик от одной или
- из столбцов B,C,
инструментов «Эксель» былоЦена на товар N
exceltable.com
февраль
Как построить график корреляции в Excel
Excel – это эффективный инструмент для статистической обработки данных. И определение корреляций является очень важной составляющей этого процесса. Программа имеет весь необходимый инструментарий для осуществления расчетов такого плана. Сегодня мы более детально разберемся, что нам нужно для осуществления анализа этого типа.
Что представляет собой корреляционный анализ
Простыми словами, корреляция – это связь между двумя явлениями. В свою очередь, под корреляционным анализом подразумевают выявление этой связи. Очень частое утверждение гласит, что корреляция – это зависимость между разными объектами, но на деле это неточное определение. Ведь существует множество изображений, которые показывают связь между явлениями, которые никак не могут быть зависимы друг от друга или одного третьего фактора, который влияет на них.
Для определения зависимости используется другой тип анализа, который называется регрессионным.
Величина, определяющая степень выраженности взаимосвязи, называется коэффициентом корреляции. Это единственная величина, которая рассчитывается корреляционным анализом по сравнению с регрессионным. Возможные вариации коэффициента корреляции могут быть в пределах от -1 до 1. Если это число положительное, взаимосвязь между динамикой изменения значений прямая. Если же отрицательное, то увеличение числа 1 приводит к аналогичному уменьшению числа 2. Если число меньше единицы по модулю, то корреляция неполная. Например, увеличение числа 1 на единицу приводит к увеличению числа 2 на 0,5. В таком случае коэффициент корреляции составляет 0,5. Если же коэффициент корреляции составляет 0, то взаимосвязи между двумя переменными нет.
Интересный факт: корреляции делятся на истинные и ложные. То есть, иногда то, что графики идут в одинаковом направлении, может быть чистой случайностью, а не закономерным следствием воздействия одной переменной на другую или влияния общего фактора на обе переменные. В узких кругах довольно популярны картинки, где коррелируют между собой абсолютно не связанные явления. Вот некоторые примеры:
- Количество человек, которые стали утопленниками в бассейнах, четко коррелирует с количеством фильмов, в которых Николас Кейдж был актером.
- Количество съеденной моцареллы и количество человек, которые получили докторскую степень, также коррелирует на протяжении 2000-2009 годов. Наверно, действительно, моцарелла как-то влияет на мозг и стимулирует желание совершать научные открытия.
- Почти во всех случаях средний возраст женщин, которые получили статус «Мисс Америка» коррелирует с количеством людей, которые погибли от нахождения в горячем паре.
- Число людей, которое погибло в результате дорожно-транспортного происшествия, четко коррелирует с количеством сметаны, которое съедают люди.
- Мало кто знает, что чем больше курятины человек ест, тем больше сырой нефти импортируется в мире. Правда, это тоже пример ложной корреляции. Кстати, импорт сырой нефти родом из Норвегии тесно связано с количеством людей, которые погибли в результате столкновения автомобиля с поездом. Причем в этом случае корреляция почти 100 процентов.
- А еще маргарин негативно влияет на статистику разводов. Чем больше людей, которые проживали в штате Мэн, потребляли маргарина, тем выше была частота разводов. Правда, здесь еще может быть рациональное зерно. Ведь частота потребления маргарина имеет обратную корреляцию с экономическим положением в семье. В свою очередь, плохое экономическое положение в семье имеет непосредственную связь с количеством разводов. И это уже доказано научно. Так что кто знает, может, эта корреляция и не является такой ложной. Правда, никто этого не перепроверял.
- Количество денег, которое правительство США тратит на развитие науки, космоса и технологий, имеет тесную связь с количеством самоубийств, проведенных в форме повешения или удушения.
Ну и наконец, еще один пример ложной корреляции – чем больше сыра люди едят, тем больше людей умирает из-за того, что они запутываются в своих простынях.
Поэтому несмотря на то, что корреляция является эффективным статистическим инструментом, нужно учиться отфильтровывать истинные взаимосвязи между явлениями и ложные. Иначе исследование может получить такие интересные результаты. А теперь переходим непосредственно к тому, как проводить корреляционный анализ в Excel.
Корреляционный анализ в Excel — 2 способа
Вычисление коэффициента корреляции осуществляется двумя способами. Первый – это использование Мастера функций, который позволяет ввести формулу КОРРЕЛ. Второй инструмент – это пакет анализа, требующий отдельной активации.
Как рассчитать коэффициент корреляции
Давайте продемонстрируем механизм получения коэффициента корреляции на реальном кейсе. Допустим, у нас есть таблица с информацией о суммах продаж и рекламу. Нам нужно понять, в какой степени количество продаж и количество денег, которые были использованы на продвижение, взаимосвязаны.
Способ 1. Определение корреляции с помощью Мастера Функций
Функция КОРРЕЛ – один из самых простых методов, как можно реализовать поставленную задачу. В своем общем виде этот оператор имеет следующий вид: КОРРЕЛ(массив1;массив2). Как же ее ввести? Для этого нужно осуществлять следующие действия:
- С помощью левой кнопки мыши выделяем ту ячейку, в которой будет находиться получившийся коэффициент корреляции. После этого находим слева от строки формул кнопку fx, которая откроет инструмент ввода функций.
- Далее выбираем категорию «Полный алфавитный перечень», в котором ищем функцию КОРРЕЛ. Как видно из названия категории, все названия функций располагаются в алфавитном порядке.
- Далее открывается окно ввода параметров функции. У нас два основных аргумента, каждый из которых являет собой массив данных, которые сравниваются между собой. В поле «Массив 1» указываем координаты первого диапазона, а в поле «Массив 2» – адрес второго диапазона. Для ввода данных массива, используемого для расчета, достаточно выделить нажать левой кнопкой мыши по соответствующему полю и выделить правильный диапазон.
- После того, как мы введем данные в аргументы, нажимаем кнопку «ОК», чем подтверждаем совершенные действия.
После выполнения описанных выше шагов мы видим в ячейке, выбранной нами на первом этапе, коэффициент корреляции. В нашем примере он составляет 0,97, что указывает на очень сильно выраженную взаимосвязь между данными двух диапазонов.
Способ 2. Вычисление корреляции с помощью пакета анализа
Также довольно неплохой инструмент для определения корреляции между двумя диапазонами – пакет анализа. Но перед тем, как его использовать, нам надо его включить. Для этого выполняем следующие действия:
- Нажимаем на кнопку «Файл», которая находится в левом верхнем углу сразу возле вкладки «Главная».
- После этого открываем раздел с настройками.
- В меню слева переходим в предпоследний пункт, озаглавленный, как «Надстройки». Делаем левый клик по соответствующей надписи.
- Открывается окно управления надстройками. Нам нужно переключить поле ввода, находящееся внизу, на пункт «Надстройки Excel» и нажать на «Перейти». Если это поле уже находится в таком положении, то не выполняем никаких изменений.
- Затем включаем пакет анализа в настройках. Для этого ставим соответствующую галочку и нажимаем на кнопку «ОК».
Все, теперь наша надстройка включена. Теперь мы во вкладке «Данные» можем увидеть кнопку «Анализ данных». Если она появилась, то мы все сделали правильно. Нажимаем на нее.
Появляется перечень с выбором разных способов анализа информации. Нам следует выбрать пункт «Корреляция» и нажать на «ОК».
Затем нам нужно ввести настройки. Основное отличие этого метода от предыдущего заключается в том, что нам нужно вводить полностью диапазон, а не разрывать его на две части. В нашем случае, это информация, указанная в двух столбцах «Затраты на рекламу» и «Величина продаж».
Не вносим никаких изменений в параметр «Группирование». По умолчанию выставлен пункт «По столбцам», и он правильный. Эта настройка определяет, каким образом программа будет разбивать данные. Если же наши данные были бы представлены в двух рядах, то надо было бы изменить этот пункт на «По строкам».
В настройках вывода уже стоит пункт «Новый рабочий лист». То есть, информация о корреляции будет располагаться на отдельном листе. Пользователь может настроить место самостоятельно с помощью соответствующего переключателя – на текущий лист или в отдельный файл. Проверяем, все ли настройки были введены правильно. Если да, подтверждаем свои действия нажатием на клавишу «ОК».
Поскольку мы оставили поле с данными о том, куда будут выводиться результаты, таким, каким оно было, мы переходим на новый лист. На нем можно найти коэффициент корреляции. Конечно, он такой же самый, как был в предыдущем методе – 0,97. Причина этого в том, что вычисления производятся одинаковые, исходные данные мы также не меняли. Просто разными методами, но не более.
Таким образом, Эксель дает сразу два метода осуществления корреляционного анализа. Как вы уже понимаете, в результате вычислений итог получится таким же. Но каждый пользователь может выбрать тот метод расчета, который ему больше всего подходит.
Как построить поле корреляции в Excel
Итак, давайте теперь разберемся, как построить поле корреляции. Для начала нужно разобраться, что это вообще такое. Под корреляционным полем подразумевается фактически график корреляции. Главное требование к такой диаграмме – каждая точка должна соответствовать единице совокупности. Поле корреляции поможет установить более глубокие связи и проанализировать данные более качественно. Для начала нам нужно найти коэффициент корреляции между двумя диапазонами, используя функцию КОРРЕЛ.
После того, как мы это сделали, мы теперь можем сделать поле корреляции. Для этого выполняем следующие действия:
- Переходим во вкладку «Вставка» и там находим вариант диаграммы «точечный график».
- После того, как мы его добавили, нажимаем по будущему полю корреляции правой кнопкой мыши и вызываем контекстное меню. Далее нажимаем на «Выбрать данные».
- Далее выбираем наш диапазон в качестве источника данных. После этого подтверждаем свои действия нажатием клавиши ОК. Все остальные действия программа выполнит самостоятельно.
Этот график можно построить не только на основе корреляции, определенной через функцию КОРРЕЛ.
Диаграмма рассеивания. Поле корреляции
До сих пор часть пользователей сидит на старой версии Word. Как построить корреляционное поле в этом случае? Для этого существует специальный инструмент, который называется мастером диаграмм. Найти его можно на панели инструментов по специфическому изображению диаграммы. Если навести на эту иконку мышкой, то появится всплывающая подсказка, которая поможет нам убедиться в том, что это действительно мастер диаграмм.
После этого появится диалоговое окно, в котором нам надо выбрать точечный тип диаграммы. Видим, что логика действий в старых версиях офисного пакета в целом остается той же самой, просто немного другой интерфейс. Немного правее мы можем увидеть, как будет выглядеть точечная диаграмма и выбрать подходящий вид, а также прочитать описание этого типа диаграммы. После этого нажимаем на кнопку «Далее».
Затем выбираем диапазон данных, и наша линия появляется. После этого можно добавить линию регрессии к графику. Для этого необходимо сделать клик правой кнопкой мыши по одной из точек и в появившемся перечне найти «Добавить линию тренда» и сделать клик по этому пункту.
Далее выставляем настройки. Нас интересует тип «Линейная», а в окне параметров нужно поставить флажок «Показывать уравнение на диаграмме».
После подтверждения действий у нас появится что-то типа такого графика.
Как видим, возможных вариантов построения может быть огромное количество.
Корреляционно-регрессионный анализ в Excel: инструкция выполнения
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2 );
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».
- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.
После активации надстройка будет доступна на вкладке «Данные».
Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).
В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.
Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» — первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» — второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.
Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:
Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
- Строим корреляционное поле: «Вставка» — «Диаграмма» — «Точечная диаграмма» (дает сравнивать пары). Диапазон значений – все числовые данные таблицы.
- Щелкаем левой кнопкой мыши по любой точке на диаграмме. Потом правой. В открывшемся меню выбираем «Добавить линию тренда».
- Назначаем параметры для линии. Тип – «Линейная». Внизу – «Показать уравнение на диаграмме».
- Жмем «Закрыть».
Теперь стали видны и данные регрессионного анализа.
Корреляционно-регрессионный анализ: пример, задачи, применение. Метод корреляционно-регрессионного анализа
Корреляционно-регрессионный анализ – это один из самых распространенных методов изучения отношений между численными величинами. Его основная цель состоит в нахождении зависимости между двумя параметрами и ее степени с последующим выведением уравнения. Например, у нас есть студенты, которые сдали экзамен по математике и английскому языку. Мы можем использовать корреляцию для того, чтобы определить, влияет ли успешность сдачи одного теста на результаты по другому предмету. Что касается регрессионного анализа, то он помогает предсказать оценки по математике, исходя из баллов, набранных на экзамене по английскому языку, и наоборот.
Что такое корреляционная диаграмма?
Любой анализ начинается со сбора информации. Чем ее больше, тем точнее полученный в конечном итоге результат. В вышеприведенном примере у нас есть две дисциплины, по которым школьникам нужно сдать экзамен. Показатель успешности на них – это оценка. Корреляционно-регрессионный анализ показывает, влияет ли результат по одному предмету на баллы, набранные на втором экзамене. Для того чтобы ответить на этот вопрос, необходимо проанализировать оценки всех учеников на параллели. Но для начала нужно определиться с зависимой переменной. В данном случае это не так важно. Допустим, экзамен по математике проходил раньше. Баллы по нему – это независимая переменная (откладываются по оси абсцисс). Английский язык стоит в расписании позже. Поэтому оценки по нему – это зависимая переменная (откладываются по оси ординат). Чем больше полученный таким образом график похож на прямую линию, тем сильнее линейная корреляция между двумя избранными величинами. Это означает, что отличники в математике с большой долей вероятности получат пятерки на экзамене по английскому.
Допущения и упрощения
Метод корреляционно-регрессионного анализа предполагает нахождение причинно-следственной связи. Однако на первом этапе нужно понимать, что изменения обеих величин могут быть обусловлены какой-нибудь третьей, пока не учтенной исследователем. Также между переменными могут быть нелинейные отношения, поэтому получение коэффициента, равного нулю, это еще не конец эксперимента.
Линейная корреляция Пирсона
Данный коэффициент может использоваться при соблюдении двух условий. Первое – все значения переменных являются рациональными числами, второе – ожидается, что величины изменяются пропорционально. Данный коэффициент всегда находится в пределах между -1 и 1. Если он больше нуля, то имеет место быть прямо пропорциональная зависимость, меньше – обратно, равен – данные величины никак не влияют одна на другую. Умение вычислить данный показатель – это основы корреляционно-регрессионного анализа. Впервые данный коэффициент был разработан Карлом Пирсоном на основе идеи Френсиса Гальтона.
Свойства и предостережения
Коэффициент корреляции Пирсона является мощным инструментом, но его также нужно использовать с осторожностью. Существуют следующие предостережения в его применении:
- Коэффициент Пирсона показывает наличие или отсутствие линейной зависимости. Корреляционно-регрессионный анализ на этом не заканчивается, может оказаться, что переменные все-таки связаны между собой.
- Нужно быть осторожным в интерпретировании значения коэффициента. Можно найти корреляцию между размером ноги и уровнем IQ. Но это не означает, что один показатель определяет другой.
- Коэффициент Пирсона не говорит ничего о причинно-следственной связи между показателями.
Коэффициент ранговой корреляции Спирмана
Если изменение величины одного показателя приводит к увеличению или уменьшению значения другого, то это означает, что они являются связанными. Корреляционно-регрессионный анализ, пример которого будет приведен ниже, как раз и связан с такими параметрами. Ранговый коэффициент позволяет упростить расчеты.
Корреляционно-регрессионный анализ: пример
Предположим, происходит оценка эффективности деятельности десяти предприятий. У нас есть двое судей, которые выставляют им баллы. Корреляционно-регрессионный анализ предприятия в этом случае не может быть проведен на основе линейного коэффициента Пирсона. Нас не интересует взаимосвязь между оценками судей. Важны ранги предприятий по оценке судей.
Данный тип анализа имеет следующие преимущества:
- Непараметрическая форма отношений между исследуемыми величинами.
- Простота использования, поскольку ранги могут приписываться как в порядке возрастания значений, так и убывания.
Единственное требование данного типа анализа – это необходимость конвертации исходных данных.
Проблемы применения
В основе корреляционно-регрессионного анализа лежат следующие предположения:
- Наблюдения считаются независимыми (пятикратное выпадение «орла» никак не влияет на результат следующего подбрасывания монетки).
- В корреляционном анализе обе переменные рассматриваются как случайные. В регрессионном – только одна (зависимая).
- При проверке гипотезы должно соблюдаться нормальное распределение. Изменение зависимой переменной должно быть одинаковым для каждой величины на оси абсцисс.
- Корреляционная диаграмма – это только первая проверка гипотезы о взаимоотношениях между двумя рядами параметров, а не конечный результат анализа.
Зависимость и причинно-следственная связь
Предположим, мы вычислили коэффициент корреляции объема экспорта и ВВП. Он оказался равным единице по модулю. Провели ли мы корреляционно-регрессионный анализ до конца? Конечно же нет. Полученный результат вовсе не означает, что ВВП можно выразить через экспорт. Мы еще не доказали причинно-следственную связь между показателями. Корреляционно-регрессионный анализ – прогнозирование значений одной переменной на основе другой. Однако нужно понимать, что зачастую на параметр влияет множество факторов. Экспорт обуславливает ВВП, но не только он. Есть и другие факторы. Здесь имеет место быть и корреляция, и причинно-следственная связь, хотя и с поправкой на другие составляющие валового внутреннего продукта.
Гораздо опаснее другая ситуация. В Великобритании был проведен опрос, который показал, что дети, родители которых курили, чаще являются правонарушителями. Такой вывод сделан на основе сильной корреляции между показателя. Однако правилен ли он? Во-первых, зависимость могла быть обратной. Родители могли начать курить из-за стресса от того, что их дети постоянно попадают в переделки и нарушают закон. Во-вторых, оба параметра могут быть обусловлены третьим. Такие семьи принадлежат к низким социальным классам, для которых характерны обе проблемы. Поэтому на основе корреляции нельзя сделать вывод о наличии причинно-следственной связи.
Зачем использовать регрессионный анализ?
Корреляционная зависимость предполагает нахождение отношений между величинами. Причинно-следственная связь в этом случае остается за кадром. Задачи корреляционного и регрессионного анализа совпадают только в плане подтверждения наличия зависимости между значениями двух величин. Однако первоначально исследователь не обращает внимания на возможность причинно-следственной связи. В регрессионном анализе всегда есть две переменные, одна и которых является зависимой. Он проходит в несколько этапов:
- Выбор правильной модели с помощью метода наименьших квадратов.
- Выведение уравнения, описывающего влияние изменения независимой переменной на другую.
Например, если мы изучаем влияние возраста на рост человека, то регрессионный анализ может помочь предсказать изменения с течением лет.
Линейная и множественная регрессия
Предположим, что X и Y – это две связанные переменные. Регрессионный анализ позволяет предсказать величину одной из них на основе значений другой. Например, зрелость и возраст – это зависимые признаки. Зависимость между ними отражается с помощью линейной регрессии. Фактически можно выразить X через Y или наоборот. Но зачастую только одна из линий регрессии оказывается правильной. Успех анализа во многом зависит от правильности определения независимой переменной. Например, у нас есть два показателя: урожайность и объем выпавших осадков. Из житейского опыта становится ясно, что первое зависит от второго, а не наоборот.
Множественная регрессия позволяет рассчитать неизвестную величину на основе значений трех и более переменных. Например, урожайность риса на акр земли зависит от качества зерна, плодородности почвы, удобрений, температуры, количества осадков. Все эти параметры влияют на совокупный результат. Для упрощения модели используются следующие допущения:
- Зависимость между независимой и влияющими на нее характеристиками является линейной.
- Мультиколлинеарность исключена. Это означает, что зависимые переменные не связаны между собой.
- Гомоскедастичность и нормальность рядов чисел.
Применение корреляционно-регрессионного анализа
Существует три основных случая использования данного метода:
- Тестирование казуальных отношений между величинами. В этом случае исследователь определяет значения переменной и выясняет, влияют ли они на изменение зависимой переменной. Например, можно дать людям разные дозы алкоголя и измерить их артериальное давление. В этом случае исследователь точно знает, что первое является причиной второго, а не наоборот. Корреляционно-регрессионный анализ позволяет обнаружить прямо-пропорциональную линейную зависимость между данными двумя переменными и вывести формулу, ее описывающую. При этом сравниваться могут величины, выраженные в совершенно различных единицах измерения.
- Нахождение зависимости между двумя переменными без распространения на них причинно-следственной связи. В этом случае нет разницы, какую величину исследователь назовет зависимой. При этом в реальности может оказаться, что на их обе влияет третья переменная, поэтому они и изменяются пропорционально.
- Расчет значений одной величины на основе другой. Он осуществляется на основе уравнения, в которое подставляются известные числа.
Таким образом корреляционный анализ предполагает нахождение связи (не причинно-следственной) между переменными, а регрессионный – ее объяснение, зачастую с помощью математической функции.
http://exceltable.com/otchety/korrelyacionno-regressionnyy-analiz
http://businessman.ru/new-korrelyacionno-regressionnyj-analiz-primer-zadachi-primenenie.html
Известна тем, что она полезна в разных областях деятельности, включая и такую дисциплину, как эконометрика, где в работе используется данная программная утилита. В основном все действия практических и лабораторных занятий выполняют в Excel, которая существенно облегчает работу, давая подробные объяснения тех или иных действий. Так, один из инструментов анализа «Регрессия» применяется с целью подбора графика для набора наблюдений за счет метода наименьших квадратов. Рассмотрим, что представляет собой данный инструмент программы и в чем заключается его польза для пользователей. Ниже также предоставлена краткая, но понятная инструкция построения регрессионной модели.
Основные задачи и виды регрессии
Регрессия представляет собой зависимость между заданными переменными, за счет чего можно определить прогноз будущего поведения данных переменных. Переменные — это различные периодические явления, включая и поведение человека. Такой анализ программы Excel применяется для того, чтобы проанализировать воздействие на конкретную зависимую переменную значений одной или некоторым количеством переменных.
К примеру, на продажи в магазине влияет несколько факторов, включая ассортимент, цены и место локализации магазина. Благодаря регрессии в Excel можно определять степень влияния каждого из указанных факторов по результатам имеющихся продаж, а после применить полученные данные для прогнозирования продаж на другой месяц или для другого магазина, расположенного рядом.
Обычно регрессия представлена в виде простого уравнения, раскрывающего зависимости и силу связи между двумя группами переменных, где одна группа является зависимой или эндогенной, а другая — независимой или экзогенной. При наличии группы взаимосвязанных показателей зависимая переменная Y определяется исходя из логики рассуждений, а остальные выступают в роли независимых Х-переменных.
Основные задачи построения регрессионной модели заключаются в следующем:
- Отбор значимых независимых переменных (Х1, Х2, …, Xk).
- Выбор вида функции.
- Построение оценок для коэффициентов.
- Построение доверительных интервалов и функции регрессии.
- Проверка значимости вычисленных оценок и построенного уравнения регрессии.
Регрессионный анализ бывает нескольких видов:
- парный (1 зависимая и 1 независимая переменные);
- множественный (несколько независимых переменных).
Уравнения регрессии бывает двух видов:
- Линейные, иллюстрирующие строгую линейную связь между переменными.
- Нелинейные — уравнения, которые могут включать степени, дроби и тригонометрические функции.
Инструкция построения модели
Чтобы выполнить заданное построение в Excel, необходимо следовать указаниям:
Для дальнейшего вычисления следует использоваться функцию «Линейн ()», указывая Значения Y, Значения Х, Конст и статистику. После этого определите множество точек на линии регрессии с помощью функции «Тенденция» — Значения Y, Значения Х, Новые значения, Конст. При помощи заданных параметров вычислите неизвестное значение коэффициентов, опираясь на заданные условия поставленной задачи.
Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
Теперь, когда мы перейдем во вкладку «Данные»
, на ленте в блоке инструментов «Анализ»
мы увидим новую кнопку – «Анализ данных»
.

Виды регрессионного анализа
Существует несколько видов регрессий:
- параболическая;
- степенная;
- логарифмическая;
- экспоненциальная;
- показательная;
- гиперболическая;
- линейная регрессия.
О выполнении последнего вида регрессионного анализа в Экселе мы подробнее поговорим далее.
Линейная регрессия в программе Excel
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк. В этой формуле Y
означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x
– это различные факторы, влияющие на переменную. Параметры a
являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k
обозначает общее количество этих самых факторов.


Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат
. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение»
и столбца «Коэффициенты»
. Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1»
и «Коэффициенты»
показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
КОРРЕЛЯЦИОННО-РЕГРЕССИОННЫЙ АНАЛИЗ В
MS
EXCEL
1. Создайте файл исходных данных в MS Excel (например, таблица 2)
2. Построение корреляционного поля
Для построения корреляционного поля в командной строке выбираем меню Вставка/ Диаграмма
. В появившемся диалоговом окне выберите тип диаграммы: Точечная
; вид: Точечная диаграмма
, позволяющая сравнить пары значений (Рис. 22).
Рисунок 22 – Выбор типа диаграммы
Рисунок 23– Вид окна при выборе диапазона и рядов
Рисунок 25 – Вид окна, шаг 4
2. В контекстном меню выбираем команду Добавить линию тренда.
3. В появившемся диалоговом окне выбираем тип графика (в нашем примере линейная) и параметры уравнения, как показано на рисунке 26.
Нажимаем ОК. Результат представлен на рисунке 27.
Рисунок 27 – Корреляционное поле зависимости производительности труда от фондовооруженности
Аналогично строим корреляционное поле зависимости производительности труда от коэффициента сменности оборудования. (рисунок 28).

Виды регрессионного анализа
|
|
Рисунок 28 – Корреляционное поле зависимости производительности труда
от коэффициента сменности оборудования
3. Построение корреляционной матрицы.
Для построения корреляционной матрицы в меню Сервис
выбираем Анализ данных.
С помощью инструмента анализа данных Регрессия
, помимо результатов регрессионной статистики, дисперсионного анализа и доверительных интервалов, можно получить остатки и графики подбора линии регрессии, остатков и нормальной вероятности. Для этого необходимо проверить доступ к пакету анализа. В главном меню последовательно выберите Сервис/ Надстройки
. Установите флажок Пакет анализа
(Рисунок 29)
Рисунок 30 – Диалоговое окно Анализ данных
После нажатия ОК в появившемся диалоговом окне указываем входной интервал (в нашем примере А2:D26), группирование (в нашем случае по столбцам) и параметры вывода, как показано на рисунке 31.
 |
Рисунок 31 – Диалоговое окно Корреляция
Результат расчетов представлен в таблице 4.
Таблица 4 – Корреляционная матрица
|
Столбец 1 |
Столбец 2 |
Столбец 3 |
|
|
Столбец 1 |
|||
|
Столбец 2 |
|||
|
Столбец 3 |
ОДНОФАКТОРНЫЙ РЕГРЕССИОННЫЙ АНАЛИЗ
С ПРИМЕНЕНИЕМ ИНСТРУМЕНТА РЕГРЕССИИ
Для проведения регрессионного анализа зависимости производительности труда от фондовооруженности в меню Сервис
выбираем Анализ данных
и указываем инструмент анализа Регрессия
(Рисунок 32).
Рисунок 33 – Диалоговое окно Регрессия
По территориям региона приводятся данные за 200Х г.
| Номер региона | Среднедушевой прожиточный минимум в день одного трудоспособного, руб., х | Среднедневная заработная плата, руб., у |
|---|---|---|
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
Задание:
1. Постройте поле корреляции и сформулируйте гипотезу о форме связи.
2. Рассчитайте параметры уравнения линейной регрессии
4. Дайте с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
7. Рассчитайте прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости .
Решение:
Решим данную задачу с помощью Excel.
1. Сопоставив имеющиеся данные х и у, например, ранжировав их в порядке возрастания фактора х, можно наблюдать наличие прямой зависимости между признаками, когда увеличение среднедушевого прожиточного минимума увеличивает среднедневную заработную плату. Исходя из этого, можно сделать предположение, что связь между признаками прямая и её можно описать уравнением прямой. Этот же вывод подтверждается и на основе графического анализа.
Чтобы построить поле корреляции можно воспользоваться ППП Excel. Введите исходные данные в последовательности: сначала х, затем у.
Выделите область ячеек, содержащую данные.
Затем выберете: Вставка / Точечная диаграмма / Точечная с маркерами
как показано на рисунке 1.

Рисунок 1 Построение поля корреляции
Анализ поля корреляции показывает наличие близкой к прямолинейной зависимости, так как точки расположены практически по прямой линии.
2. Для расчёта параметров уравнения линейной регрессии
воспользуемся встроенной статистической функцией ЛИНЕЙН
.
Для этого:
1) Откройте существующий файл, содержащий анализируемые данные;
2) Выделите область пустых ячеек 5×2 (5 строк, 2 столбца) для вывода результатов регрессионной статистики.
3) Активизируйте Мастер функций
: в главном меню выберете Формулы / Вставить функцию
.
4) В окне Категория
выберете Статистические
, в окне функция — ЛИНЕЙН
. Щёлкните по кнопке ОК
как показано на Рисунке 2;

Рисунок 2 Диалоговое окно «Мастер функций»
5) Заполните аргументы функции:
Известные значения у
Известные значения х
Константа
— логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении; если Константа = 1, то свободный член рассчитывается обычным образом, если Константа = 0, то свободный член равен 0;
Статистика
— логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если Статистика = 0, то выводятся только оценки параметров уравнения.
Щёлкните по кнопке ОК
;

Рисунок 3 Диалоговое окно аргументов функции ЛИНЕЙН
6) В левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу
, а затем на комбинацию клавиш ++
.
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
![]()
Рисунок 31 – Диалоговое окно Корреляция
Результат расчетов представлен в таблице 4.
Таблица 4 – Корреляционная матрица
|
Столбец 1 |
Столбец 2 |
Столбец 3 |
|
|
Столбец 1 |
|||
|
Столбец 2 |
|||
|
Столбец 3 |
ОДНОФАКТОРНЫЙ РЕГРЕССИОННЫЙ АНАЛИЗ
С ПРИМЕНЕНИЕМ ИНСТРУМЕНТА РЕГРЕССИИ
Для проведения регрессионного анализа зависимости производительности труда от фондовооруженности в меню Сервис
выбираем Анализ данных
и указываем инструмент анализа Регрессия
(Рисунок 32).
Рисунок 33 – Диалоговое окно Регрессия
По территориям региона приводятся данные за 200Х г.
| Номер региона | Среднедушевой прожиточный минимум в день одного трудоспособного, руб., х | Среднедневная заработная плата, руб., у |
|---|---|---|
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
Задание:
1. Постройте поле корреляции и сформулируйте гипотезу о форме связи.
2. Рассчитайте параметры уравнения линейной регрессии
4. Дайте с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
7. Рассчитайте прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости .
Решение:
Решим данную задачу с помощью Excel.
1. Сопоставив имеющиеся данные х и у, например, ранжировав их в порядке возрастания фактора х, можно наблюдать наличие прямой зависимости между признаками, когда увеличение среднедушевого прожиточного минимума увеличивает среднедневную заработную плату. Исходя из этого, можно сделать предположение, что связь между признаками прямая и её можно описать уравнением прямой. Этот же вывод подтверждается и на основе графического анализа.
Чтобы построить поле корреляции можно воспользоваться ППП Excel. Введите исходные данные в последовательности: сначала х, затем у.
Выделите область ячеек, содержащую данные.
Затем выберете: Вставка / Точечная диаграмма / Точечная с маркерами
как показано на рисунке 1.
Рисунок 1 Построение поля корреляции
Анализ поля корреляции показывает наличие близкой к прямолинейной зависимости, так как точки расположены практически по прямой линии.
2. Для расчёта параметров уравнения линейной регрессии
воспользуемся встроенной статистической функцией ЛИНЕЙН
.
Для этого:
1) Откройте существующий файл, содержащий анализируемые данные;
2) Выделите область пустых ячеек 5×2 (5 строк, 2 столбца) для вывода результатов регрессионной статистики.
3) Активизируйте Мастер функций
: в главном меню выберете Формулы / Вставить функцию
.
4) В окне Категория
выберете Статистические
, в окне функция — ЛИНЕЙН
. Щёлкните по кнопке ОК
как показано на Рисунке 2;
Рисунок 2 Диалоговое окно «Мастер функций»
5) Заполните аргументы функции:
Известные значения у
Известные значения х
Константа
— логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении; если Константа = 1, то свободный член рассчитывается обычным образом, если Константа = 0, то свободный член равен 0;
Статистика
— логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если Статистика = 0, то выводятся только оценки параметров уравнения.
Щёлкните по кнопке ОК
;
Рисунок 3 Диалоговое окно аргументов функции ЛИНЕЙН
6) В левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу
, а затем на комбинацию клавиш ++
.
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:

| Значение коэффициента b | Значение коэффициента a |
| Стандартная ошибка b | Стандартная ошибка a |
| Стандартная ошибка y | |
| F-статистика | |
| Регрессионная сумма квадратов
|

Рисунок 4 Результат вычисления функции ЛИНЕЙН
Получили уровнение регрессии:
Делаем вывод: С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.
Означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х — среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
По вычисленному коэффициенту детерминации можно рассчитать коэффициент корреляции: ![]()
Рисунок 4 Результат вычисления функции ЛИНЕЙН
Получили уровнение регрессии:
Делаем вывод: С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.
Означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х — среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
По вычисленному коэффициенту детерминации можно рассчитать коэффициент корреляции:  .
.
Связь оценивается как тесная.
4. С помощью среднего (общего) коэффициента эластичности определим силу влияния фактора на результат.
Для уравнения прямой средний (общий) коэффициент эластичности определим по формуле:

Средние значения найдём, выделив область ячеек со значениями х, и выберем Формулы / Автосумма / Среднее
, и то же самое произведём со значениями у.

Рисунок 5 Расчёт средних значений функции и аргумент
Таким образом, при изменении среднедушевого прожиточного минимума на 1% от своего среднего значения среднедневная заработная плата изменится в среднем на 0,51%.
С помощью инструмента анализа данных Регрессия
можно получить:
— результаты регрессионной статистики,
— результаты дисперсионного анализа,
— результаты доверительных интервалов,
— остатки и графики подбора линии регрессии,
— остатки и нормальную вероятность.
Порядок действий следующий:
1) проверьте доступ к Пакету анализа
. В главном меню последовательно выберите: Файл/Параметры/Надстройки
.
2) В раскрывающемся списке Управление
выберите пункт Надстройки Excel
и нажмите кнопку Перейти.
3) В окне Надстройки
установите флажок Пакет анализа
, а затем нажмите кнопку ОК
.
Если Пакет анализа
отсутствует в списке поля Доступные надстройки
, нажмите кнопку Обзор
, чтобы выполнить поиск.
Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да
, чтобы установить его.
4) В главном меню последовательно выберите: Данные / Анализ данных / Инструменты анализа / Регрессия
, а затем нажмите кнопку ОК
.
5) Заполните диалоговое окно ввода данных и параметров вывода:
Входной интервал Y
— диапазон, содержащий данные результативного признака;
Входной интервал X
— диапазон, содержащий данные факторного признака;
Метки
— флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Константа — ноль
— флажок, указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал
— достаточно указать левую верхнюю ячейку будущего диапазона;
6) Новый рабочий лист — можно задать произвольное имя нового листа.
Затем нажмите кнопку ОК
.

Рисунок 6 Диалоговое окно ввода параметров инструмента Регрессия
Результаты регрессионного анализа для данных задачи представлены на рисунке 7.

Рисунок 7 Результат применения инструмента регрессия
5. Оценим с помощью средней ошибки аппроксимации качество уравнений. Воспользуемся результатами регрессионного анализа представленного на Рисунке 8.

Рисунок 8 Результат применения инструмента регрессия «Вывод остатка»
Составим новую таблицу как показано на рисунке 9. В графе С рассчитаем относительную ошибку аппроксимации по формуле:
![]()
Средние значения найдём, выделив область ячеек со значениями х, и выберем Формулы / Автосумма / Среднее
, и то же самое произведём со значениями у.
Рисунок 5 Расчёт средних значений функции и аргумент
Таким образом, при изменении среднедушевого прожиточного минимума на 1% от своего среднего значения среднедневная заработная плата изменится в среднем на 0,51%.
С помощью инструмента анализа данных Регрессия
можно получить:
— результаты регрессионной статистики,
— результаты дисперсионного анализа,
— результаты доверительных интервалов,
— остатки и графики подбора линии регрессии,
— остатки и нормальную вероятность.
Порядок действий следующий:
1) проверьте доступ к Пакету анализа
. В главном меню последовательно выберите: Файл/Параметры/Надстройки
.
2) В раскрывающемся списке Управление
выберите пункт Надстройки Excel
и нажмите кнопку Перейти.
3) В окне Надстройки
установите флажок Пакет анализа
, а затем нажмите кнопку ОК
.
Если Пакет анализа
отсутствует в списке поля Доступные надстройки
, нажмите кнопку Обзор
, чтобы выполнить поиск.
Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да
, чтобы установить его.
4) В главном меню последовательно выберите: Данные / Анализ данных / Инструменты анализа / Регрессия
, а затем нажмите кнопку ОК
.
5) Заполните диалоговое окно ввода данных и параметров вывода:
Входной интервал Y
— диапазон, содержащий данные результативного признака;
Входной интервал X
— диапазон, содержащий данные факторного признака;
Метки
— флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Константа — ноль
— флажок, указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал
— достаточно указать левую верхнюю ячейку будущего диапазона;
6) Новый рабочий лист — можно задать произвольное имя нового листа.
Затем нажмите кнопку ОК
.
Рисунок 6 Диалоговое окно ввода параметров инструмента Регрессия
Результаты регрессионного анализа для данных задачи представлены на рисунке 7.
Рисунок 7 Результат применения инструмента регрессия
5. Оценим с помощью средней ошибки аппроксимации качество уравнений. Воспользуемся результатами регрессионного анализа представленного на Рисунке 8.
Рисунок 8 Результат применения инструмента регрессия «Вывод остатка»
Составим новую таблицу как показано на рисунке 9. В графе С рассчитаем относительную ошибку аппроксимации по формуле:


Рисунок 9 Расчёт средней ошибки аппроксимации
Средняя ошибка аппроксимации рассчитывается по формуле:

Рисунок 9 Расчёт средней ошибки аппроксимации
Средняя ошибка аппроксимации рассчитывается по формуле:
Качество построенной модели оценивается как хорошее, так как не превышает 8 — 10%.
6. Из таблицы с регрессионной статистикой (Рисунок 4) выпишем фактическое значение F-критерия Фишера: ![]()
Поскольку ![]()
Поскольку  при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
8. Оценку статистической значимости параметров регрессии проведём с помощью t-статистики Стьюдента и путём расчёта доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н 0 о статистически незначимом отличии показателей от нуля:
![]() .
.
![]() .
.
 для числа степеней свободы
для числа степеней свободы
На рисунке 7 имеются фактические значения t-статистики:
t-критерий для коэффициента корреляции можно рассчитать двумя способами:
I способ:
где  — случайная ошибка коэффициента корреляции.
— случайная ошибка коэффициента корреляции.
Данные для расчёта возьмём из таблицы на Рисунке 7.
 — случайная ошибка коэффициента корреляции.
— случайная ошибка коэффициента корреляции.
Данные для расчёта возьмём из таблицы на Рисунке 7.
II способ:
Фактические значения t-статистики превосходят табличные значения:
Поэтому гипотеза Н 0 отклоняется, то есть параметры регрессии и коэффициент корреляции не случайно отличаются от нуля, а статистически значимы.
Доверительный интервал для параметра a определяется как
![]()
Для параметра a 95%-ные границы как показано на рисунке 7 составили:
Доверительный интервал для коэффициента регрессии определяется как
![]()
Для параметра a 95%-ные границы как показано на рисунке 7 составили:
Доверительный интервал для коэффициента регрессии определяется как

Для коэффициента регрессии b 95%-ные границы как показано на рисунке 7 составили:
![]()
Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью ![]()
Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью  параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
7. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение прожиточного минимума составит:
Тогда прогнозное значение прожиточного минимума составит:
Ошибку прогноза рассчитаем по формуле:

где ![]()
где 
Дисперсию посчитаем также с помощью ППП Excel. Для этого:
1) Активизируйте Мастер функций
: в главном меню выберете Формулы / Вставить функцию
.
3) Заполните диапазон, содержащий числовые данные факторного признака. Нажмите ОК
.

Рисунок 10 Расчёт дисперсии
Получили значение дисперсии ![]()
Рисунок 10 Расчёт дисперсии
Получили значение дисперсии 
Для подсчёта остаточной дисперсии на одну степень свободы воспользуемся результатами дисперсионного анализа как показано на Рисунке 7.

Доверительные интервалы прогноза индивидуальных значений у при с вероятностью 0,95 определяются выражением:
![]()
Доверительные интервалы прогноза индивидуальных значений у при с вероятностью 0,95 определяются выражением:

Интервал достаточно широк, прежде всего, за счёт малого объёма наблюдений. В целом выполненный прогноз среднемесячной заработной платы оказался надёжным.
Условие задачи взято из: Практикум по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. — М.: Финансы и статистика, 2003. — 192 с.: ил.
Статистическая обработка данных может также проводиться с помощью надстройки ПАКЕТ АНАЛИЗА
(рис. 62).
Из предложенных пунктов выбирает пункт «РЕГРЕССИЯ
» и щелкаем на нем левой кнопкой мыши. Далее нажимаем ОК.
Появится окно, показанное на рис. 63.

Инструмент анализа «РЕГРЕССИЯ
» применяется для подбора графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или нескольких независимых переменных. Например, на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Можно вычислить степень влияния каждого из этих трех факторов по результатам выступления спортсмена, а затем использовать полученные данные для предсказания выступления другого спортсмена.
Инструмент «Регрессия» использует функцию ЛИНЕЙН
.
Диалоговое окно «РЕГРЕССИЯ»
Метки Установите флажок, если первая строка или первый столбец входного диапазона содержит заголовки. Снимите этот флажок, если заголовки отсутствуют. В этом случае подходящие заголовки для данных выходной таблицы будут созданы автоматически.
Уровень надежности Установите флажок, чтобы включить в выходную таблицу итогов дополнительный уровень. В соответствующее поле введите уровень надежности, который следует применить, дополнительно к уровню 95%, применяемому по умолчанию.
Константа — ноль Установите флажок, чтобы линия регрессии прошла через начало координат.
Выходной интервал Введите ссылку на левую верхнюю ячейку выходного диапазона. Отведите как минимум семь столбцов для выходной таблицы итогов, которая будет включать в себя: результаты дисперсионного анализа, коэффициенты, стандартную погрешность вычисления Y, среднеквадратичные отклонения, число наблюдений, стандартные погрешности для коэффициентов.
Новый рабочий лист Установите переключатель в это положение, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки A1. При необходимости введите имя для нового листа в поле, расположенном напротив соответствующего положения переключателя.
Новая рабочая книга Установите переключатель в это положение для создания новой книги, в которой результаты будут добавлены в новый лист.
Остатки Установите флажок для включения остатков в выходную таблицу.
Стандартизированные остатки Установите флажок для включения стандартизированных остатков в выходную таблицу.
График остатков Установите флажок для построения графика остатков для каждой независимой переменной.
График подбора Установите флажок для построения графика зависимости предсказанных значений от наблюдаемых.
График нормальной вероятности
Установите флажок, для построения графика нормальной вероятности.
Функция ЛИНЕЙН
Для проведения расчетов выделяем курсором ячейку, в которой хотим отобразить среднее значение и нажимаем на клавиатуре клавишу =. Далее в поле Имя указываем нужную функцию, например СРЗНАЧ
(рис. 22).
Функция ЛИНЕЙН
рассчитывает статистику для ряда с применением метода наименьших квадратов, чтобы вычислить прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные и затем возвращает массив, который описывает полученную прямую. Можно также объединять функцию ЛИНЕЙН
с другими функциями для вычисления других видов моделей, являющихся линейными в неизвестных параметрах (неизвестные параметры которых являются линейными), включая полиномиальные, логарифмические, экспоненциальные и степенные ряды. Поскольку возвращается массив значений, функция должна задаваться в виде формулы массива.
Уравнение для прямой линии имеет следующий вид:
y=m 1 x 1 +m 2 x 2 +…+b (в случае нескольких диапазонов значений x),
где зависимое значение y — функция независимого значения x, значения m — коэффициенты, соответствующие каждой независимой переменной x, а b — постоянная. Обратите внимание, что y, x и m могут быть векторами. Функция ЛИНЕЙН
возвращает массив{mn;mn-1;…;m 1 ;b}. ЛИНЕЙН
может также возвращать дополнительную регрессионную статистику.
ЛИНЕЙН
(известные_значения_y; известные_значения_x; конст; статистика)
Известные_значения_y — множество значений y, которые уже известны для соотношения y=mx+b.
Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_x интерпретируется как отдельная переменная.
Если массив известные_значения_y имеет одну строку, то каждая строка массива известные_значения_x интерпретируется как отдельная переменная.
Известные_значения_x — необязательное множество значений x, которые уже известны для соотношения y=mx+b.
Массив известные_значения_x может содержать одно или несколько множеств переменных. Если используется только одна переменная, то массивы_известные_значения_y и известные_значения_x могут иметь любую форму — при условии, что они имеют одинаковую размерность. Если используется более одной переменной, то известные_значения_y должны быть вектором (т. е. интервалом высотой в одну строку или шириной в один столбец).
Если массив_известные_значения_x опущен, то предполагается, что этот массив {1;2;3;…} имеет такой же размер, как и массив_известные_значения_y.
Конст — логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0.
Если аргумент «конст» имеет значение ИСТИНА или опущен, то константа b вычисляется обычным образом.
Если аргумент «конст» имеет значение ЛОЖЬ, то значение b полагается равным 0 и значения m подбираются таким образом, чтобы выполнялось соотношение y=mx.
Статистика — логическое значение, которое указывает, требуется ли вернуть дополнительную статистику по регрессии.
Если аргумент «статистика» имеет значение ИСТИНА, функция ЛИНЕЙН возвращает дополнительную регрессионную статистику. Возвращаемый массив будет иметь следующий вид: {mn;mn-1;…;m1;b:sen;sen-1;…;se1;seb:r2;sey:F;df:ssreg;ssresid}.
Если аргумент «статистика» имеет значение ЛОЖЬ или опущен, функция ЛИНЕЙН возвращает только коэффициенты m и постоянную b.
Дополнительная регрессионная статистика.(табл.17)
| Величина | Описание |
| se1,se2,…,sen | Стандартные значения ошибок для коэффициентов m1,m2,…,mn. |
| seb | Стандартное значение ошибки для постоянной b (seb = #Н/Д, если аргумент «конст» имеет значение ЛОЖЬ). |
| r2 | Коэффициент детерминированности. Сравниваются фактические значения y и значения, получаемые из уравнения прямой; по результатам сравнения вычисляется коэффициент детерминированности, нормированный от 0 до 1. Если он равен 1, то имеет место полная корреляция с моделью, т. е. различия между фактическим и оценочным значениями y не существует. В противоположном случае, если коэффициент детерминированности равен 0, использовать уравнение регрессии для предсказания значений y не имеет смысла. Для получения дополнительных сведений о способах вычисления r2, см. «Замечания» в конце данного раздела. |
| sey | Стандартная ошибка для оценки y. |
| F | F-статистика или F-наблюдаемое значение. F-статистика используется для определения того, является ли случайной наблюдаемая взаимосвязь между зависимой и независимой переменными. |
| df | Степени свободы. Степени свободы полезны для нахождения F-критических значений в статистической таблице. Для определения уровня надежности модели необходимо сравнить значения в таблице с F-статистикой, возвращаемой функцией ЛИНЕЙН. Для получения дополнительных сведений о вычислении величины df см. «Замечания» в конце данного раздела. Далее в примере 4 показано использование величин F и df. |
| ssreg | Регрессионная сумма квадратов. |
| ssresid | Остаточная сумма квадратов. Для получения дополнительных сведений о расчете величин ssreg и ssresid см. «Замечания» в конце данного раздела. |
На приведенном ниже рисунке показано, в каком порядке возвращается дополнительная регрессионная статистика (рис. 64).

Инструмент анализа «РЕГРЕССИЯ
» применяется для подбора графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или нескольких независимых переменных. Например, на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Можно вычислить степень влияния каждого из этих трех факторов по результатам выступления спортсмена, а затем использовать полученные данные для предсказания выступления другого спортсмена.
Инструмент «Регрессия» использует функцию ЛИНЕЙН
.
Диалоговое окно «РЕГРЕССИЯ»
Метки Установите флажок, если первая строка или первый столбец входного диапазона содержит заголовки. Снимите этот флажок, если заголовки отсутствуют. В этом случае подходящие заголовки для данных выходной таблицы будут созданы автоматически.
Уровень надежности Установите флажок, чтобы включить в выходную таблицу итогов дополнительный уровень. В соответствующее поле введите уровень надежности, который следует применить, дополнительно к уровню 95%, применяемому по умолчанию.
Константа — ноль Установите флажок, чтобы линия регрессии прошла через начало координат.
Выходной интервал Введите ссылку на левую верхнюю ячейку выходного диапазона. Отведите как минимум семь столбцов для выходной таблицы итогов, которая будет включать в себя: результаты дисперсионного анализа, коэффициенты, стандартную погрешность вычисления Y, среднеквадратичные отклонения, число наблюдений, стандартные погрешности для коэффициентов.
Новый рабочий лист Установите переключатель в это положение, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки A1. При необходимости введите имя для нового листа в поле, расположенном напротив соответствующего положения переключателя.
Новая рабочая книга Установите переключатель в это положение для создания новой книги, в которой результаты будут добавлены в новый лист.
Остатки Установите флажок для включения остатков в выходную таблицу.
Стандартизированные остатки Установите флажок для включения стандартизированных остатков в выходную таблицу.
График остатков Установите флажок для построения графика остатков для каждой независимой переменной.
График подбора Установите флажок для построения графика зависимости предсказанных значений от наблюдаемых.
График нормальной вероятности
Установите флажок, для построения графика нормальной вероятности.
Функция ЛИНЕЙН
Для проведения расчетов выделяем курсором ячейку, в которой хотим отобразить среднее значение и нажимаем на клавиатуре клавишу =. Далее в поле Имя указываем нужную функцию, например СРЗНАЧ
(рис. 22).
Функция ЛИНЕЙН
рассчитывает статистику для ряда с применением метода наименьших квадратов, чтобы вычислить прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные и затем возвращает массив, который описывает полученную прямую. Можно также объединять функцию ЛИНЕЙН
с другими функциями для вычисления других видов моделей, являющихся линейными в неизвестных параметрах (неизвестные параметры которых являются линейными), включая полиномиальные, логарифмические, экспоненциальные и степенные ряды. Поскольку возвращается массив значений, функция должна задаваться в виде формулы массива.
Уравнение для прямой линии имеет следующий вид:
y=m 1 x 1 +m 2 x 2 +…+b (в случае нескольких диапазонов значений x),
где зависимое значение y — функция независимого значения x, значения m — коэффициенты, соответствующие каждой независимой переменной x, а b — постоянная. Обратите внимание, что y, x и m могут быть векторами. Функция ЛИНЕЙН
возвращает массив{mn;mn-1;…;m 1 ;b}. ЛИНЕЙН
может также возвращать дополнительную регрессионную статистику.
ЛИНЕЙН
(известные_значения_y; известные_значения_x; конст; статистика)
Известные_значения_y — множество значений y, которые уже известны для соотношения y=mx+b.
Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_x интерпретируется как отдельная переменная.
Если массив известные_значения_y имеет одну строку, то каждая строка массива известные_значения_x интерпретируется как отдельная переменная.
Известные_значения_x — необязательное множество значений x, которые уже известны для соотношения y=mx+b.
Массив известные_значения_x может содержать одно или несколько множеств переменных. Если используется только одна переменная, то массивы_известные_значения_y и известные_значения_x могут иметь любую форму — при условии, что они имеют одинаковую размерность. Если используется более одной переменной, то известные_значения_y должны быть вектором (т. е. интервалом высотой в одну строку или шириной в один столбец).
Если массив_известные_значения_x опущен, то предполагается, что этот массив {1;2;3;…} имеет такой же размер, как и массив_известные_значения_y.
Конст — логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0.
Если аргумент «конст» имеет значение ИСТИНА или опущен, то константа b вычисляется обычным образом.
Если аргумент «конст» имеет значение ЛОЖЬ, то значение b полагается равным 0 и значения m подбираются таким образом, чтобы выполнялось соотношение y=mx.
Статистика — логическое значение, которое указывает, требуется ли вернуть дополнительную статистику по регрессии.
Если аргумент «статистика» имеет значение ИСТИНА, функция ЛИНЕЙН возвращает дополнительную регрессионную статистику. Возвращаемый массив будет иметь следующий вид: {mn;mn-1;…;m1;b:sen;sen-1;…;se1;seb:r2;sey:F;df:ssreg;ssresid}.
Если аргумент «статистика» имеет значение ЛОЖЬ или опущен, функция ЛИНЕЙН возвращает только коэффициенты m и постоянную b.
Дополнительная регрессионная статистика.(табл.17)
| Величина | Описание |
| se1,se2,…,sen | Стандартные значения ошибок для коэффициентов m1,m2,…,mn. |
| seb | Стандартное значение ошибки для постоянной b (seb = #Н/Д, если аргумент «конст» имеет значение ЛОЖЬ). |
| r2 | Коэффициент детерминированности. Сравниваются фактические значения y и значения, получаемые из уравнения прямой; по результатам сравнения вычисляется коэффициент детерминированности, нормированный от 0 до 1. Если он равен 1, то имеет место полная корреляция с моделью, т. е. различия между фактическим и оценочным значениями y не существует. В противоположном случае, если коэффициент детерминированности равен 0, использовать уравнение регрессии для предсказания значений y не имеет смысла. Для получения дополнительных сведений о способах вычисления r2, см. «Замечания» в конце данного раздела. |
| sey | Стандартная ошибка для оценки y. |
| F | F-статистика или F-наблюдаемое значение. F-статистика используется для определения того, является ли случайной наблюдаемая взаимосвязь между зависимой и независимой переменными. |
| df | Степени свободы. Степени свободы полезны для нахождения F-критических значений в статистической таблице. Для определения уровня надежности модели необходимо сравнить значения в таблице с F-статистикой, возвращаемой функцией ЛИНЕЙН. Для получения дополнительных сведений о вычислении величины df см. «Замечания» в конце данного раздела. Далее в примере 4 показано использование величин F и df. |
| ssreg | Регрессионная сумма квадратов. |
| ssresid | Остаточная сумма квадратов. Для получения дополнительных сведений о расчете величин ssreg и ssresid см. «Замечания» в конце данного раздела. |
На приведенном ниже рисунке показано, в каком порядке возвращается дополнительная регрессионная статистика (рис. 64).
Замечания:
Любую прямую можно описать ее наклоном и пересечением с осью y:
Наклон (m): чтобы определить наклон прямой, обычно обозначаемый через m, нужно взять две точки прямой (x 1 ,y 1) и(x 2 ,y 2); наклон будет равен (y 2 -y 1)/(x 2 -x 1).
Y-пересечение (b): Y-пересечением прямой, обычно обозначаемым через b, является значение y для точки, в которой прямая пересекает ось y.
Уравнение прямой имеет вид y=mx+b. Если известны значения m и b, то можно вычислить любую точку на прямой, подставляя значения y или x в уравнение. Можно также воспользоваться функцией ТЕНДЕНЦИЯ.
Если имеется только одна независимая переменная x, можно получить наклон и y-пересечение непосредственно, воспользовавшись следующими формулами:
Наклон: ИНДЕКС (ЛИНЕЙН(известные_значения_y; известные_значения_x); 1)
Y-пересечение: ИНДЕКС (ЛИНЕЙН (известные_значения_y; известные_значения_x); 2)
Точность аппроксимации с помощью прямой, вычисленной функцией ЛИНЕЙН, зависит от степени разброса данных. Чем ближе данные к прямой, тем более точной является модель, используемая функцией ЛИНЕЙН. Функция ЛИНЕЙН использует метод наименьших квадратов для определения наилучшей аппроксимации данных. Когда имеется только одна независимая переменная x, m и b вычисляются по следующим формулам:

где x и y – выборочные средние значения, например x = СРЗНАЧ (известные_значения_x), а y = СРЗНАЧ (известные_значения_y).
Функции аппроксимации ЛИНЕЙН и ЛГРФПРИБЛ могут вычислить прямую или экспоненциальную кривую, наилучшим образом описывающую данные. Однако они не дают ответа на вопрос, какой из двух результатов больше подходит для решения поставленной задачи. Можно также вычислить функцию ТЕНДЕНЦИЯ (известные_значения_y; известные_значения_x) для прямой или функцию РОСТ(известные_значения_y; известные_значения_x) для экспоненциальной кривой. Эти функции, если не задавать аргумент новые_значения_x, возвращают массив вычисленных значений y для фактических значений x в соответствии с прямой или кривой. После этого можно сравнить вычисленные значения с фактическими значениями. Можно также построить диаграммы для визуального сравнения.
Проводя регрессионный анализ, Microsoft Excel вычисляет для каждой точки квадрат разности между прогнозируемым значением y и фактическим значением y. Сумма этих квадратов разностей называется остаточной суммой квадратов (ssresid). Затем Microsoft Excel подсчитывает общую сумму квадратов (sstotal). Если конст = ИСТИНА или значение этого аргумента не указано, общая сумма квадратов будет равна сумме квадратов разностей действительных значений y и средних значений y. При конст = ЛОЖЬ общая сумма квадратов будет равна сумме квадратов действительных значений y (без вычитания среднего значения y из частного значения y). После этого регрессионную сумму квадратов можно вычислить следующим образом: ssreg = sstotal — ssresid. Чем меньше остаточная сумма квадратов, тем больше значение коэффициента детерминированности r2, который показывает, насколько хорошо уравнение, полученное с помощью регрессионного анализа, объясняет взаимосвязи между переменными. Коэффициент r2 равен ssreg/sstotal.
В некоторых случаях один или более столбцов X (пусть значения Y и X находятся в столбцах) не имеет дополнительного предикативного значения в других столбцах X. Другими словами, удаление одного или более столбцов X может привести к значениям Y, вычисленным с одинаковой точностью. В этом случае избыточные столбцы X будут исключены из модели регрессии. Этот феномен называется «коллинеарностью», поскольку избыточные столбцы X могут быть представлены в виде суммы нескольких неизбыточных столбцов. Функция ЛИНЕЙН проверяет на коллинеарность и удаляет из модели регрессии все избыточные столбцы X, если обнаруживает их. Удаленные столбцы X можно определить в выходных данных ЛИНЕЙН по коэффициенту, равному 0, и по значению se, равному 0. Удаление одного или более столбцов как избыточных изменяет величину df, поскольку она зависит от количества столбцов X, в действительности используемых для предикативных целей. Подробнее о вычислении величины df см. ниже в примере 4. При изменении df вследствие удаления избыточных столбцов значения sey и F также изменяются. Часто использовать коллинеарность не рекомендуется. Однако ее следует применять, если некоторые столбцы X содержат 0 или 1 в качестве индикатора указывающего, входит ли предмет эксперимента в отдельную группу. Если конст = ИСТИНА или значение этого аргумента не указано, функция ЛИНЕЙН вставляет дополнительный столбец X для моделирования точки пересечения. Если имеется столбец со значениями 1 для указания мужчин и 0 — для женщин, а также имеется столбец со значениями 1 для указания женщин и 0 — для мужчин, то последний столбец удаляется, поскольку его значения можно получить из столбца с «индикатором мужского пола».
Вычисление df для случаев, когда столбцы X не удаляются из модели вследствие коллинеарности происходит следующим образом: если существует k столбцов известных_значений_x и значение конст = ИСТИНА или не указано, то df = n – k – 1. Если конст = ЛОЖЬ, то df = n — k. В обоих случаях удаление столбцов X вследствие коллинеарности увеличивает значение df на 1.
Формулы, которые возвращают массивы, должны быть введены как формулы массива.
При вводе массива констант в качестве, например, аргумента известные_значения_x следует использовать точку с запятой для разделения значений в одной строке и двоеточие для разделения строк. Знаки-разделители могут быть различными в зависимости от параметров, заданных в окне «Язык и стандарты» на панели управления.
Следует отметить, что значения y, предсказанные с помощью уравнения регрессии, возможно, не будут правильными, если они располагаются вне интервала значений y, которые использовались для определения уравнения.
Основной алгоритм, используемый в функции ЛИНЕЙН
, отличается от основного алгоритма функций НАКЛОН
и ОТРЕЗОК
. Разница между алгоритмами может привести к различным результатам при неопределенных и коллинеарных данных. Например, если точки данных аргумента известные_значения_y равны 0, а точки данных аргумента известные_значения_x равны 1, то:
Функция ЛИНЕЙН
возвращает значение, равное 0. Алгоритм функции ЛИНЕЙН
используется для возвращения подходящих значений для коллинеарных данных, и в данном случае может быть найден по меньшей мере один ответ.
Функции НАКЛОН и ОТРЕЗОК возвращают ошибку #ДЕЛ/0!. Алгоритм функций НАКЛОН и ОТРЕЗОК используется для поиска только одного ответа, а в данном случае их может быть несколько.
Помимо вычисления статистики для других типов регрессии функцию ЛИНЕЙН можно использовать при вычислении диапазонов для других типов регрессии, вводя функции переменных x и y как ряды переменных х и у для ЛИНЕЙН. Например, следующая формула:
ЛИНЕЙН(значения_y, значения_x^СТОЛБЕЦ($A:$C))
работает при наличии одного столбца значений Y и одного столбца значений Х для вычисления аппроксимации куба (многочлен 3-й степени) следующей формы:
y=m 1 x+m 2 x 2 +m 3 x 3 +b
Формула может быть изменена для расчетов других типов регрессии, но в отдельных случаях требуется корректировка выходных значений и других статистических данных.